class: center, middle, inverse, title-slide # Data wrangling --- class: inverse, center, top background-image: url(https://github.com/allisonhorst/stats-illustrations/blob/master/rstats-artwork/dplyr_wrangling.png?raw=true) background-size: 650px background-position: 50% 85% # the `dplyr` package --- background-image: url(https://raw.githubusercontent.com/rstudio/hex-stickers/master/PNG/dplyr.png) background-size: 120px background-position: 92% 5% ## the `dplyr` package Functions are thought of as **verbs** that manipulate data frames - `filter()`: pick rows by matching some criteria - `slice()` pick rows using index(es) - `select()`: select columns of a data frame by name - `pull()`: grab a column as a vector - `arrange()`: reorder the rows of a data frame - `mutate()`: add new or change existing columns of the data frame (as functions of existing columns) - `summarize()`: collapse many values down into a summary of the data frame - ... These can all be used with `group_by()` which changes the scope of function from entire dataset to group-by-group. --- background-image: url(https://raw.githubusercontent.com/rstudio/hex-stickers/master/PNG/dplyr.png) background-size: 120px background-position: 92% 5% ## the `dplyr` package Rules for functions: - First argument is always a data frame - Subsequent arguments say what to do with that data frame - Always return a data frame - Don't modify in place <br/> A note on piping and layering: - The `%>%` operator in dplyr functions is called the "pipe operator". - This means you "pipe" the output of the previous line of code as the first input of the next line of code. - The `+` operator in ggplot2 functions is used for "layering". - This means you create the plot in layers, separated by `+`. --- ## `filter()` select a subset of the observations (horizontal selection): `filter(.data, ...)` specify constraints (as logical expression) to data in ... all constraints are combined by logical and & .left-third[ <style>html { font-family: -apple-system, BlinkMacSystemFont, 'Segoe UI', Roboto, Oxygen, Ubuntu, Cantarell, 'Helvetica Neue', 'Fira Sans', 'Droid Sans', Arial, sans-serif; } #fjujoxialy .gt_table { display: table; border-collapse: collapse; margin-left: auto; margin-right: auto; color: #333333; font-size: 16px; background-color: #FFFFFF; /* table.background.color */ width: auto; /* table.width */ border-top-style: solid; /* table.border.top.style */ border-top-width: 2px; /* table.border.top.width */ border-top-color: #A8A8A8; /* table.border.top.color */ border-bottom-style: solid; /* table.border.bottom.style */ border-bottom-width: 2px; /* table.border.bottom.width */ border-bottom-color: #A8A8A8; /* table.border.bottom.color */ } #fjujoxialy .gt_heading { background-color: #FFFFFF; /* heading.background.color */ border-bottom-color: #FFFFFF; } #fjujoxialy .gt_title { color: #333333; font-size: 125%; /* heading.title.font.size */ padding-top: 4px; /* heading.top.padding - not yet used */ padding-bottom: 4px; border-bottom-color: #FFFFFF; border-bottom-width: 0; } #fjujoxialy .gt_subtitle { color: #333333; font-size: 85%; /* heading.subtitle.font.size */ padding-top: 0; padding-bottom: 4px; /* heading.bottom.padding - not yet used */ border-top-color: #FFFFFF; border-top-width: 0; } #fjujoxialy .gt_bottom_border { border-bottom-style: solid; /* heading.border.bottom.style */ border-bottom-width: 2px; /* heading.border.bottom.width */ border-bottom-color: #D3D3D3; /* heading.border.bottom.color */ } #fjujoxialy .gt_column_spanner { border-bottom-style: solid; border-bottom-width: 2px; border-bottom-color: #D3D3D3; padding-top: 4px; padding-bottom: 4px; } #fjujoxialy .gt_col_heading { color: #333333; background-color: #FFFFFF; /* column_labels.background.color */ font-size: 16px; /* column_labels.font.size */ font-weight: initial; /* column_labels.font.weight */ vertical-align: middle; padding: 5px; margin: 10px; overflow-x: hidden; } #fjujoxialy .gt_columns_top_border { border-top-style: solid; border-top-width: 2px; border-top-color: #D3D3D3; } #fjujoxialy .gt_columns_bottom_border { border-bottom-style: solid; border-bottom-width: 2px; border-bottom-color: #D3D3D3; } #fjujoxialy .gt_sep_right { border-right: 5px solid #FFFFFF; } #fjujoxialy .gt_group_heading { padding: 8px; /* row_group.padding */ color: #333333; background-color: #FFFFFF; /* row_group.background.color */ font-size: 16px; /* row_group.font.size */ font-weight: initial; /* row_group.font.weight */ border-top-style: solid; /* row_group.border.top.style */ border-top-width: 2px; /* row_group.border.top.width */ border-top-color: #D3D3D3; /* row_group.border.top.color */ border-bottom-style: solid; /* row_group.border.bottom.style */ border-bottom-width: 2px; /* row_group.border.bottom.width */ border-bottom-color: #D3D3D3; /* row_group.border.bottom.color */ vertical-align: middle; } #fjujoxialy .gt_empty_group_heading { padding: 0.5px; color: #333333; background-color: #FFFFFF; /* row_group.background.color */ font-size: 16px; /* row_group.font.size */ font-weight: initial; /* row_group.font.weight */ border-top-style: solid; /* row_group.border.top.style */ border-top-width: 2px; /* row_group.border.top.width */ border-top-color: #D3D3D3; /* row_group.border.top.color */ border-bottom-style: solid; /* row_group.border.bottom.style */ border-bottom-width: 2px; /* row_group.border.bottom.width */ border-bottom-color: #D3D3D3; /* row_group.border.bottom.color */ vertical-align: middle; } #fjujoxialy .gt_striped { background-color: #8080800D; } #fjujoxialy .gt_from_md > :first-child { margin-top: 0; } #fjujoxialy .gt_from_md > :last-child { margin-bottom: 0; } #fjujoxialy .gt_row { padding: 8px; /* row.padding */ margin: 10px; border-top-style: solid; border-top-width: 1px; border-top-color: #D3D3D3; vertical-align: middle; overflow-x: hidden; } #fjujoxialy .gt_stub { border-right-style: solid; border-right-width: 2px; border-right-color: #D3D3D3; padding-left: 12px; } #fjujoxialy .gt_summary_row { color: #333333; background-color: #FFFFFF; /* summary_row.background.color */ padding: 8px; /* summary_row.padding */ text-transform: inherit; /* summary_row.text_transform */ } #fjujoxialy .gt_grand_summary_row { color: #333333; background-color: #FFFFFF; /* grand_summary_row.background.color */ padding: 8px; /* grand_summary_row.padding */ text-transform: inherit; /* grand_summary_row.text_transform */ } #fjujoxialy .gt_first_summary_row { border-top-style: solid; border-top-width: 2px; border-top-color: #D3D3D3; } #fjujoxialy .gt_first_grand_summary_row { border-top-style: double; border-top-width: 6px; border-top-color: #D3D3D3; } #fjujoxialy .gt_table_body { border-top-style: solid; /* table_body.border.top.style */ border-top-width: 2px; /* table_body.border.top.width */ border-top-color: #D3D3D3; /* table_body.border.top.color */ border-bottom-style: solid; /* table_body.border.bottom.style */ border-bottom-width: 2px; /* table_body.border.bottom.width */ border-bottom-color: #D3D3D3; /* table_body.border.bottom.color */ } #fjujoxialy .gt_footnotes { border-top-style: solid; /* footnotes.border.top.style */ border-top-width: 2px; /* footnotes.border.top.width */ border-top-color: #D3D3D3; /* footnotes.border.top.color */ } #fjujoxialy .gt_footnote { font-size: 90%; /* footnote.font.size */ margin: 0px; padding: 4px; /* footnote.padding */ } #fjujoxialy .gt_sourcenotes { border-top-style: solid; /* sourcenotes.border.top.style */ border-top-width: 2px; /* sourcenotes.border.top.width */ border-top-color: #D3D3D3; /* sourcenotes.border.top.color */ } #fjujoxialy .gt_sourcenote { font-size: 90%; /* sourcenote.font.size */ padding: 4px; /* sourcenote.padding */ } #fjujoxialy .gt_center { text-align: center; } #fjujoxialy .gt_left { text-align: left; } #fjujoxialy .gt_right { text-align: right; font-variant-numeric: tabular-nums; } #fjujoxialy .gt_font_normal { font-weight: normal; } #fjujoxialy .gt_font_bold { font-weight: bold; } #fjujoxialy .gt_font_italic { font-style: italic; } #fjujoxialy .gt_super { font-size: 65%; } #fjujoxialy .gt_footnote_marks { font-style: italic; font-size: 65%; } </style> <div id="fjujoxialy" style="overflow-x:auto;overflow-y:auto;width:auto;height:auto;"><table class="gt_table" style="table-layout: fixed; width: 180px"> <colgroup> <col style="width: 60px"/> <col style="width: 60px"/> <col style="width: 60px"/> </colgroup> <tr> <th class="gt_col_heading gt_columns_bottom_border gt_columns_top_border gt_left" rowspan="1" colspan="1"> </th> <th class="gt_col_heading gt_columns_bottom_border gt_columns_top_border gt_left" rowspan="1" colspan="1"> </th> <th class="gt_col_heading gt_columns_bottom_border gt_columns_top_border gt_left" rowspan="1" colspan="1"> </th> </tr> <body class="gt_table_body"> <tr> <td class="gt_row gt_left" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> </tr> <tr> <td class="gt_row gt_left gt_striped" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left gt_striped" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left gt_striped" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> </tr> <tr> <td class="gt_row gt_left" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> </tr> <tr> <td class="gt_row gt_left gt_striped" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left gt_striped" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left gt_striped" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> </tr> <tr> <td class="gt_row gt_left" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> </tr> <tr> <td class="gt_row gt_left gt_striped" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left gt_striped" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left gt_striped" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> </tr> <tr> <td class="gt_row gt_left" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> </tr> <tr> <td class="gt_row gt_left gt_striped" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left gt_striped" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left gt_striped" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> </tr> <tr> <td class="gt_row gt_left" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> </tr> <tr> <td class="gt_row gt_left gt_striped" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left gt_striped" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left gt_striped" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> </tr> <tr> <td class="gt_row gt_left" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> </tr> <tr> <td class="gt_row gt_left gt_striped" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left gt_striped" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left gt_striped" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> </tr> <tr> <td class="gt_row gt_left" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> </tr> <tr> <td class="gt_row gt_left gt_striped" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left gt_striped" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left gt_striped" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> </tr> <tr> <td class="gt_row gt_left" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> </tr> </body> </table></div> ] .right-two-thirds[ .pull-left[ <style>html { font-family: -apple-system, BlinkMacSystemFont, 'Segoe UI', Roboto, Oxygen, Ubuntu, Cantarell, 'Helvetica Neue', 'Fira Sans', 'Droid Sans', Arial, sans-serif; } #acpikkpyqv .gt_table { display: table; border-collapse: collapse; margin-left: auto; margin-right: auto; color: #333333; font-size: 16px; background-color: #FFFFFF; /* table.background.color */ width: auto; /* table.width */ border-top-style: solid; /* table.border.top.style */ border-top-width: 2px; /* table.border.top.width */ border-top-color: #A8A8A8; /* table.border.top.color */ border-bottom-style: solid; /* table.border.bottom.style */ border-bottom-width: 2px; /* table.border.bottom.width */ border-bottom-color: #A8A8A8; /* table.border.bottom.color */ } #acpikkpyqv .gt_heading { background-color: #FFFFFF; /* heading.background.color */ border-bottom-color: #FFFFFF; } #acpikkpyqv .gt_title { color: #333333; font-size: 125%; /* heading.title.font.size */ padding-top: 4px; /* heading.top.padding - not yet used */ padding-bottom: 4px; border-bottom-color: #FFFFFF; border-bottom-width: 0; } #acpikkpyqv .gt_subtitle { color: #333333; font-size: 85%; /* heading.subtitle.font.size */ padding-top: 0; padding-bottom: 4px; /* heading.bottom.padding - not yet used */ border-top-color: #FFFFFF; border-top-width: 0; } #acpikkpyqv .gt_bottom_border { border-bottom-style: solid; /* heading.border.bottom.style */ border-bottom-width: 2px; /* heading.border.bottom.width */ border-bottom-color: #D3D3D3; /* heading.border.bottom.color */ } #acpikkpyqv .gt_column_spanner { border-bottom-style: solid; border-bottom-width: 2px; border-bottom-color: #D3D3D3; padding-top: 4px; padding-bottom: 4px; } #acpikkpyqv .gt_col_heading { color: #333333; background-color: #FFFFFF; /* column_labels.background.color */ font-size: 16px; /* column_labels.font.size */ font-weight: initial; /* column_labels.font.weight */ vertical-align: middle; padding: 5px; margin: 10px; overflow-x: hidden; } #acpikkpyqv .gt_columns_top_border { border-top-style: solid; border-top-width: 2px; border-top-color: #D3D3D3; } #acpikkpyqv .gt_columns_bottom_border { border-bottom-style: solid; border-bottom-width: 2px; border-bottom-color: #D3D3D3; } #acpikkpyqv .gt_sep_right { border-right: 5px solid #FFFFFF; } #acpikkpyqv .gt_group_heading { padding: 8px; /* row_group.padding */ color: #333333; background-color: #FFFFFF; /* row_group.background.color */ font-size: 16px; /* row_group.font.size */ font-weight: initial; /* row_group.font.weight */ border-top-style: solid; /* row_group.border.top.style */ border-top-width: 2px; /* row_group.border.top.width */ border-top-color: #D3D3D3; /* row_group.border.top.color */ border-bottom-style: solid; /* row_group.border.bottom.style */ border-bottom-width: 2px; /* row_group.border.bottom.width */ border-bottom-color: #D3D3D3; /* row_group.border.bottom.color */ vertical-align: middle; } #acpikkpyqv .gt_empty_group_heading { padding: 0.5px; color: #333333; background-color: #FFFFFF; /* row_group.background.color */ font-size: 16px; /* row_group.font.size */ font-weight: initial; /* row_group.font.weight */ border-top-style: solid; /* row_group.border.top.style */ border-top-width: 2px; /* row_group.border.top.width */ border-top-color: #D3D3D3; /* row_group.border.top.color */ border-bottom-style: solid; /* row_group.border.bottom.style */ border-bottom-width: 2px; /* row_group.border.bottom.width */ border-bottom-color: #D3D3D3; /* row_group.border.bottom.color */ vertical-align: middle; } #acpikkpyqv .gt_striped { background-color: #8080800D; } #acpikkpyqv .gt_from_md > :first-child { margin-top: 0; } #acpikkpyqv .gt_from_md > :last-child { margin-bottom: 0; } #acpikkpyqv .gt_row { padding: 8px; /* row.padding */ margin: 10px; border-top-style: solid; border-top-width: 1px; border-top-color: #D3D3D3; vertical-align: middle; overflow-x: hidden; } #acpikkpyqv .gt_stub { border-right-style: solid; border-right-width: 2px; border-right-color: #D3D3D3; padding-left: 12px; } #acpikkpyqv .gt_summary_row { color: #333333; background-color: #FFFFFF; /* summary_row.background.color */ padding: 8px; /* summary_row.padding */ text-transform: inherit; /* summary_row.text_transform */ } #acpikkpyqv .gt_grand_summary_row { color: #333333; background-color: #FFFFFF; /* grand_summary_row.background.color */ padding: 8px; /* grand_summary_row.padding */ text-transform: inherit; /* grand_summary_row.text_transform */ } #acpikkpyqv .gt_first_summary_row { border-top-style: solid; border-top-width: 2px; border-top-color: #D3D3D3; } #acpikkpyqv .gt_first_grand_summary_row { border-top-style: double; border-top-width: 6px; border-top-color: #D3D3D3; } #acpikkpyqv .gt_table_body { border-top-style: solid; /* table_body.border.top.style */ border-top-width: 2px; /* table_body.border.top.width */ border-top-color: #D3D3D3; /* table_body.border.top.color */ border-bottom-style: solid; /* table_body.border.bottom.style */ border-bottom-width: 2px; /* table_body.border.bottom.width */ border-bottom-color: #D3D3D3; /* table_body.border.bottom.color */ } #acpikkpyqv .gt_footnotes { border-top-style: solid; /* footnotes.border.top.style */ border-top-width: 2px; /* footnotes.border.top.width */ border-top-color: #D3D3D3; /* footnotes.border.top.color */ } #acpikkpyqv .gt_footnote { font-size: 90%; /* footnote.font.size */ margin: 0px; padding: 4px; /* footnote.padding */ } #acpikkpyqv .gt_sourcenotes { border-top-style: solid; /* sourcenotes.border.top.style */ border-top-width: 2px; /* sourcenotes.border.top.width */ border-top-color: #D3D3D3; /* sourcenotes.border.top.color */ } #acpikkpyqv .gt_sourcenote { font-size: 90%; /* sourcenote.font.size */ padding: 4px; /* sourcenote.padding */ } #acpikkpyqv .gt_center { text-align: center; } #acpikkpyqv .gt_left { text-align: left; } #acpikkpyqv .gt_right { text-align: right; font-variant-numeric: tabular-nums; } #acpikkpyqv .gt_font_normal { font-weight: normal; } #acpikkpyqv .gt_font_bold { font-weight: bold; } #acpikkpyqv .gt_font_italic { font-style: italic; } #acpikkpyqv .gt_super { font-size: 65%; } #acpikkpyqv .gt_footnote_marks { font-style: italic; font-size: 65%; } </style> <div id="acpikkpyqv" style="overflow-x:auto;overflow-y:auto;width:auto;height:auto;"><table class="gt_table" style="table-layout: fixed; width: 180px"> <colgroup> <col style="width: 60px"/> <col style="width: 60px"/> <col style="width: 60px"/> </colgroup> <tr> <th class="gt_col_heading gt_columns_bottom_border gt_columns_top_border gt_left" rowspan="1" colspan="1"> </th> <th class="gt_col_heading gt_columns_bottom_border gt_columns_top_border gt_left" rowspan="1" colspan="1"> </th> <th class="gt_col_heading gt_columns_bottom_border gt_columns_top_border gt_left" rowspan="1" colspan="1"> </th> </tr> <body class="gt_table_body"> <tr> <td class="gt_row gt_left" style="background-color: #9ACD32FF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left" style="background-color: #9ACD32FF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left" style="background-color: #9ACD32FF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> </tr> <tr> <td class="gt_row gt_left gt_striped" style="background-color: #9ACD32FF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left gt_striped" style="background-color: #9ACD32FF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left gt_striped" style="background-color: #9ACD32FF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> </tr> <tr> <td class="gt_row gt_left" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> </tr> <tr> <td class="gt_row gt_left gt_striped" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left gt_striped" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left gt_striped" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> </tr> <tr> <td class="gt_row gt_left" style="background-color: #9ACD32FF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left" style="background-color: #9ACD32FF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left" style="background-color: #9ACD32FF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> </tr> <tr> <td class="gt_row gt_left gt_striped" style="background-color: #9ACD32FF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left gt_striped" style="background-color: #9ACD32FF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left gt_striped" style="background-color: #9ACD32FF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> </tr> <tr> <td class="gt_row gt_left" style="background-color: #9ACD32FF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left" style="background-color: #9ACD32FF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left" style="background-color: #9ACD32FF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> </tr> <tr> <td class="gt_row gt_left gt_striped" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left gt_striped" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left gt_striped" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> </tr> <tr> <td class="gt_row gt_left" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> </tr> <tr> <td class="gt_row gt_left gt_striped" style="background-color: #9ACD32FF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left gt_striped" style="background-color: #9ACD32FF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left gt_striped" style="background-color: #9ACD32FF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> </tr> <tr> <td class="gt_row gt_left" style="background-color: #9ACD32FF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left" style="background-color: #9ACD32FF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left" style="background-color: #9ACD32FF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> </tr> <tr> <td class="gt_row gt_left gt_striped" style="background-color: #9ACD32FF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left gt_striped" style="background-color: #9ACD32FF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left gt_striped" style="background-color: #9ACD32FF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> </tr> <tr> <td class="gt_row gt_left" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> </tr> <tr> <td class="gt_row gt_left gt_striped" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left gt_striped" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left gt_striped" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> </tr> <tr> <td class="gt_row gt_left" style="background-color: #9ACD32FF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left" style="background-color: #9ACD32FF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left" style="background-color: #9ACD32FF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> </tr> </body> </table></div> ] .pull-right[ <style>html { font-family: -apple-system, BlinkMacSystemFont, 'Segoe UI', Roboto, Oxygen, Ubuntu, Cantarell, 'Helvetica Neue', 'Fira Sans', 'Droid Sans', Arial, sans-serif; } #sldyqnevrg .gt_table { display: table; border-collapse: collapse; margin-left: auto; margin-right: auto; color: #333333; font-size: 16px; background-color: #FFFFFF; /* table.background.color */ width: auto; /* table.width */ border-top-style: solid; /* table.border.top.style */ border-top-width: 2px; /* table.border.top.width */ border-top-color: #A8A8A8; /* table.border.top.color */ border-bottom-style: solid; /* table.border.bottom.style */ border-bottom-width: 2px; /* table.border.bottom.width */ border-bottom-color: #A8A8A8; /* table.border.bottom.color */ } #sldyqnevrg .gt_heading { background-color: #FFFFFF; /* heading.background.color */ border-bottom-color: #FFFFFF; } #sldyqnevrg .gt_title { color: #333333; font-size: 125%; /* heading.title.font.size */ padding-top: 4px; /* heading.top.padding - not yet used */ padding-bottom: 4px; border-bottom-color: #FFFFFF; border-bottom-width: 0; } #sldyqnevrg .gt_subtitle { color: #333333; font-size: 85%; /* heading.subtitle.font.size */ padding-top: 0; padding-bottom: 4px; /* heading.bottom.padding - not yet used */ border-top-color: #FFFFFF; border-top-width: 0; } #sldyqnevrg .gt_bottom_border { border-bottom-style: solid; /* heading.border.bottom.style */ border-bottom-width: 2px; /* heading.border.bottom.width */ border-bottom-color: #D3D3D3; /* heading.border.bottom.color */ } #sldyqnevrg .gt_column_spanner { border-bottom-style: solid; border-bottom-width: 2px; border-bottom-color: #D3D3D3; padding-top: 4px; padding-bottom: 4px; } #sldyqnevrg .gt_col_heading { color: #333333; background-color: #FFFFFF; /* column_labels.background.color */ font-size: 16px; /* column_labels.font.size */ font-weight: initial; /* column_labels.font.weight */ vertical-align: middle; padding: 5px; margin: 10px; overflow-x: hidden; } #sldyqnevrg .gt_columns_top_border { border-top-style: solid; border-top-width: 2px; border-top-color: #D3D3D3; } #sldyqnevrg .gt_columns_bottom_border { border-bottom-style: solid; border-bottom-width: 2px; border-bottom-color: #D3D3D3; } #sldyqnevrg .gt_sep_right { border-right: 5px solid #FFFFFF; } #sldyqnevrg .gt_group_heading { padding: 8px; /* row_group.padding */ color: #333333; background-color: #FFFFFF; /* row_group.background.color */ font-size: 16px; /* row_group.font.size */ font-weight: initial; /* row_group.font.weight */ border-top-style: solid; /* row_group.border.top.style */ border-top-width: 2px; /* row_group.border.top.width */ border-top-color: #D3D3D3; /* row_group.border.top.color */ border-bottom-style: solid; /* row_group.border.bottom.style */ border-bottom-width: 2px; /* row_group.border.bottom.width */ border-bottom-color: #D3D3D3; /* row_group.border.bottom.color */ vertical-align: middle; } #sldyqnevrg .gt_empty_group_heading { padding: 0.5px; color: #333333; background-color: #FFFFFF; /* row_group.background.color */ font-size: 16px; /* row_group.font.size */ font-weight: initial; /* row_group.font.weight */ border-top-style: solid; /* row_group.border.top.style */ border-top-width: 2px; /* row_group.border.top.width */ border-top-color: #D3D3D3; /* row_group.border.top.color */ border-bottom-style: solid; /* row_group.border.bottom.style */ border-bottom-width: 2px; /* row_group.border.bottom.width */ border-bottom-color: #D3D3D3; /* row_group.border.bottom.color */ vertical-align: middle; } #sldyqnevrg .gt_striped { background-color: #8080800D; } #sldyqnevrg .gt_from_md > :first-child { margin-top: 0; } #sldyqnevrg .gt_from_md > :last-child { margin-bottom: 0; } #sldyqnevrg .gt_row { padding: 8px; /* row.padding */ margin: 10px; border-top-style: solid; border-top-width: 1px; border-top-color: #D3D3D3; vertical-align: middle; overflow-x: hidden; } #sldyqnevrg .gt_stub { border-right-style: solid; border-right-width: 2px; border-right-color: #D3D3D3; padding-left: 12px; } #sldyqnevrg .gt_summary_row { color: #333333; background-color: #FFFFFF; /* summary_row.background.color */ padding: 8px; /* summary_row.padding */ text-transform: inherit; /* summary_row.text_transform */ } #sldyqnevrg .gt_grand_summary_row { color: #333333; background-color: #FFFFFF; /* grand_summary_row.background.color */ padding: 8px; /* grand_summary_row.padding */ text-transform: inherit; /* grand_summary_row.text_transform */ } #sldyqnevrg .gt_first_summary_row { border-top-style: solid; border-top-width: 2px; border-top-color: #D3D3D3; } #sldyqnevrg .gt_first_grand_summary_row { border-top-style: double; border-top-width: 6px; border-top-color: #D3D3D3; } #sldyqnevrg .gt_table_body { border-top-style: solid; /* table_body.border.top.style */ border-top-width: 2px; /* table_body.border.top.width */ border-top-color: #D3D3D3; /* table_body.border.top.color */ border-bottom-style: solid; /* table_body.border.bottom.style */ border-bottom-width: 2px; /* table_body.border.bottom.width */ border-bottom-color: #D3D3D3; /* table_body.border.bottom.color */ } #sldyqnevrg .gt_footnotes { border-top-style: solid; /* footnotes.border.top.style */ border-top-width: 2px; /* footnotes.border.top.width */ border-top-color: #D3D3D3; /* footnotes.border.top.color */ } #sldyqnevrg .gt_footnote { font-size: 90%; /* footnote.font.size */ margin: 0px; padding: 4px; /* footnote.padding */ } #sldyqnevrg .gt_sourcenotes { border-top-style: solid; /* sourcenotes.border.top.style */ border-top-width: 2px; /* sourcenotes.border.top.width */ border-top-color: #D3D3D3; /* sourcenotes.border.top.color */ } #sldyqnevrg .gt_sourcenote { font-size: 90%; /* sourcenote.font.size */ padding: 4px; /* sourcenote.padding */ } #sldyqnevrg .gt_center { text-align: center; } #sldyqnevrg .gt_left { text-align: left; } #sldyqnevrg .gt_right { text-align: right; font-variant-numeric: tabular-nums; } #sldyqnevrg .gt_font_normal { font-weight: normal; } #sldyqnevrg .gt_font_bold { font-weight: bold; } #sldyqnevrg .gt_font_italic { font-style: italic; } #sldyqnevrg .gt_super { font-size: 65%; } #sldyqnevrg .gt_footnote_marks { font-style: italic; font-size: 65%; } </style> <div id="sldyqnevrg" style="overflow-x:auto;overflow-y:auto;width:auto;height:auto;"><table class="gt_table" style="table-layout: fixed; width: 180px"> <colgroup> <col style="width: 60px"/> <col style="width: 60px"/> <col style="width: 60px"/> </colgroup> <tr> <th class="gt_col_heading gt_columns_bottom_border gt_columns_top_border gt_left" rowspan="1" colspan="1"> </th> <th class="gt_col_heading gt_columns_bottom_border gt_columns_top_border gt_left" rowspan="1" colspan="1"> </th> <th class="gt_col_heading gt_columns_bottom_border gt_columns_top_border gt_left" rowspan="1" colspan="1"> </th> </tr> <body class="gt_table_body"> <tr> <td class="gt_row gt_left" style="background-color: #9ACD32FF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left" style="background-color: #9ACD32FF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left" style="background-color: #9ACD32FF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> </tr> <tr> <td class="gt_row gt_left gt_striped" style="background-color: #9ACD32FF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left gt_striped" style="background-color: #9ACD32FF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left gt_striped" style="background-color: #9ACD32FF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> </tr> <tr> <td class="gt_row gt_left" style="background-color: #9ACD32FF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left" style="background-color: #9ACD32FF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left" style="background-color: #9ACD32FF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> </tr> <tr> <td class="gt_row gt_left gt_striped" style="background-color: #9ACD32FF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left gt_striped" style="background-color: #9ACD32FF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left gt_striped" style="background-color: #9ACD32FF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> </tr> <tr> <td class="gt_row gt_left" style="background-color: #9ACD32FF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left" style="background-color: #9ACD32FF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left" style="background-color: #9ACD32FF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> </tr> <tr> <td class="gt_row gt_left gt_striped" style="background-color: #9ACD32FF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left gt_striped" style="background-color: #9ACD32FF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left gt_striped" style="background-color: #9ACD32FF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> </tr> <tr> <td class="gt_row gt_left" style="background-color: #9ACD32FF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left" style="background-color: #9ACD32FF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left" style="background-color: #9ACD32FF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> </tr> <tr> <td class="gt_row gt_left gt_striped" style="background-color: #9ACD32FF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left gt_striped" style="background-color: #9ACD32FF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left gt_striped" style="background-color: #9ACD32FF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> </tr> <tr> <td class="gt_row gt_left" style="background-color: #9ACD32FF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left" style="background-color: #9ACD32FF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left" style="background-color: #9ACD32FF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> </tr> </body> </table></div> ]] .footnote[ Make sure to always call `library(dplyr)` before using `filter()` ] --- ## `filter()` EXAMPLE From the `fbi` data, extract all burglaries in 2014: ```r library(classdata) library(dplyr) fbi %>% dplyr::filter(Type == "Burglary", Year == 2014) %>% head() ``` ``` ## State Abb Year Population Type Count Violent.crime ## 1 Alabama AL 2014 4849377 Burglary 39715 FALSE ## 2 Alaska AK 2014 736732 Burglary 3150 FALSE ## 3 Arizona AZ 2014 6731484 Burglary 43562 FALSE ## 4 Arkansas AR 2014 2966369 Burglary 24790 FALSE ## 5 California CA 2014 38802500 Burglary 202670 FALSE ## 6 Colorado CO 2014 5355866 Burglary 23472 FALSE ``` --- ## `arrange()` `arrange()` sorts a data set by the values in one or more variables - successive variables break ties in previous ones - `desc()` stands for descending, otherwise rows are sorted from smallest to largest .left-third[ <style>html { font-family: -apple-system, BlinkMacSystemFont, 'Segoe UI', Roboto, Oxygen, Ubuntu, Cantarell, 'Helvetica Neue', 'Fira Sans', 'Droid Sans', Arial, sans-serif; } #bpkfbthhut .gt_table { display: table; border-collapse: collapse; margin-left: auto; margin-right: auto; color: #333333; font-size: 16px; background-color: #FFFFFF; /* table.background.color */ width: auto; /* table.width */ border-top-style: solid; /* table.border.top.style */ border-top-width: 2px; /* table.border.top.width */ border-top-color: #A8A8A8; /* table.border.top.color */ border-bottom-style: solid; /* table.border.bottom.style */ border-bottom-width: 2px; /* table.border.bottom.width */ border-bottom-color: #A8A8A8; /* table.border.bottom.color */ } #bpkfbthhut .gt_heading { background-color: #FFFFFF; /* heading.background.color */ border-bottom-color: #FFFFFF; } #bpkfbthhut .gt_title { color: #333333; font-size: 125%; /* heading.title.font.size */ padding-top: 4px; /* heading.top.padding - not yet used */ padding-bottom: 4px; border-bottom-color: #FFFFFF; border-bottom-width: 0; } #bpkfbthhut .gt_subtitle { color: #333333; font-size: 85%; /* heading.subtitle.font.size */ padding-top: 0; padding-bottom: 4px; /* heading.bottom.padding - not yet used */ border-top-color: #FFFFFF; border-top-width: 0; } #bpkfbthhut .gt_bottom_border { border-bottom-style: solid; /* heading.border.bottom.style */ border-bottom-width: 2px; /* heading.border.bottom.width */ border-bottom-color: #D3D3D3; /* heading.border.bottom.color */ } #bpkfbthhut .gt_column_spanner { border-bottom-style: solid; border-bottom-width: 2px; border-bottom-color: #D3D3D3; padding-top: 4px; padding-bottom: 4px; } #bpkfbthhut .gt_col_heading { color: #333333; background-color: #FFFFFF; /* column_labels.background.color */ font-size: 16px; /* column_labels.font.size */ font-weight: initial; /* column_labels.font.weight */ vertical-align: middle; padding: 5px; margin: 10px; overflow-x: hidden; } #bpkfbthhut .gt_columns_top_border { border-top-style: solid; border-top-width: 2px; border-top-color: #D3D3D3; } #bpkfbthhut .gt_columns_bottom_border { border-bottom-style: solid; border-bottom-width: 2px; border-bottom-color: #D3D3D3; } #bpkfbthhut .gt_sep_right { border-right: 5px solid #FFFFFF; } #bpkfbthhut .gt_group_heading { padding: 8px; /* row_group.padding */ color: #333333; background-color: #FFFFFF; /* row_group.background.color */ font-size: 16px; /* row_group.font.size */ font-weight: initial; /* row_group.font.weight */ border-top-style: solid; /* row_group.border.top.style */ border-top-width: 2px; /* row_group.border.top.width */ border-top-color: #D3D3D3; /* row_group.border.top.color */ border-bottom-style: solid; /* row_group.border.bottom.style */ border-bottom-width: 2px; /* row_group.border.bottom.width */ border-bottom-color: #D3D3D3; /* row_group.border.bottom.color */ vertical-align: middle; } #bpkfbthhut .gt_empty_group_heading { padding: 0.5px; color: #333333; background-color: #FFFFFF; /* row_group.background.color */ font-size: 16px; /* row_group.font.size */ font-weight: initial; /* row_group.font.weight */ border-top-style: solid; /* row_group.border.top.style */ border-top-width: 2px; /* row_group.border.top.width */ border-top-color: #D3D3D3; /* row_group.border.top.color */ border-bottom-style: solid; /* row_group.border.bottom.style */ border-bottom-width: 2px; /* row_group.border.bottom.width */ border-bottom-color: #D3D3D3; /* row_group.border.bottom.color */ vertical-align: middle; } #bpkfbthhut .gt_striped { background-color: #8080800D; } #bpkfbthhut .gt_from_md > :first-child { margin-top: 0; } #bpkfbthhut .gt_from_md > :last-child { margin-bottom: 0; } #bpkfbthhut .gt_row { padding: 8px; /* row.padding */ margin: 10px; border-top-style: solid; border-top-width: 1px; border-top-color: #D3D3D3; vertical-align: middle; overflow-x: hidden; } #bpkfbthhut .gt_stub { border-right-style: solid; border-right-width: 2px; border-right-color: #D3D3D3; padding-left: 12px; } #bpkfbthhut .gt_summary_row { color: #333333; background-color: #FFFFFF; /* summary_row.background.color */ padding: 8px; /* summary_row.padding */ text-transform: inherit; /* summary_row.text_transform */ } #bpkfbthhut .gt_grand_summary_row { color: #333333; background-color: #FFFFFF; /* grand_summary_row.background.color */ padding: 8px; /* grand_summary_row.padding */ text-transform: inherit; /* grand_summary_row.text_transform */ } #bpkfbthhut .gt_first_summary_row { border-top-style: solid; border-top-width: 2px; border-top-color: #D3D3D3; } #bpkfbthhut .gt_first_grand_summary_row { border-top-style: double; border-top-width: 6px; border-top-color: #D3D3D3; } #bpkfbthhut .gt_table_body { border-top-style: solid; /* table_body.border.top.style */ border-top-width: 2px; /* table_body.border.top.width */ border-top-color: #D3D3D3; /* table_body.border.top.color */ border-bottom-style: solid; /* table_body.border.bottom.style */ border-bottom-width: 2px; /* table_body.border.bottom.width */ border-bottom-color: #D3D3D3; /* table_body.border.bottom.color */ } #bpkfbthhut .gt_footnotes { border-top-style: solid; /* footnotes.border.top.style */ border-top-width: 2px; /* footnotes.border.top.width */ border-top-color: #D3D3D3; /* footnotes.border.top.color */ } #bpkfbthhut .gt_footnote { font-size: 90%; /* footnote.font.size */ margin: 0px; padding: 4px; /* footnote.padding */ } #bpkfbthhut .gt_sourcenotes { border-top-style: solid; /* sourcenotes.border.top.style */ border-top-width: 2px; /* sourcenotes.border.top.width */ border-top-color: #D3D3D3; /* sourcenotes.border.top.color */ } #bpkfbthhut .gt_sourcenote { font-size: 90%; /* sourcenote.font.size */ padding: 4px; /* sourcenote.padding */ } #bpkfbthhut .gt_center { text-align: center; } #bpkfbthhut .gt_left { text-align: left; } #bpkfbthhut .gt_right { text-align: right; font-variant-numeric: tabular-nums; } #bpkfbthhut .gt_font_normal { font-weight: normal; } #bpkfbthhut .gt_font_bold { font-weight: bold; } #bpkfbthhut .gt_font_italic { font-style: italic; } #bpkfbthhut .gt_super { font-size: 65%; } #bpkfbthhut .gt_footnote_marks { font-style: italic; font-size: 65%; } </style> <div id="bpkfbthhut" style="overflow-x:auto;overflow-y:auto;width:auto;height:auto;"><table class="gt_table" style="table-layout: fixed; width: 180px"> <colgroup> <col style="width: 60px"/> <col style="width: 60px"/> <col style="width: 60px"/> </colgroup> <tr> <th class="gt_col_heading gt_columns_bottom_border gt_columns_top_border gt_left" rowspan="1" colspan="1"> </th> <th class="gt_col_heading gt_columns_bottom_border gt_columns_top_border gt_left" rowspan="1" colspan="1"> </th> <th class="gt_col_heading gt_columns_bottom_border gt_columns_top_border gt_left" rowspan="1" colspan="1"> </th> </tr> <body class="gt_table_body"> <tr> <td class="gt_row gt_left" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> </tr> <tr> <td class="gt_row gt_left gt_striped" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left gt_striped" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left gt_striped" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> </tr> <tr> <td class="gt_row gt_left" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> </tr> <tr> <td class="gt_row gt_left gt_striped" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left gt_striped" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left gt_striped" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> </tr> <tr> <td class="gt_row gt_left" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> </tr> <tr> <td class="gt_row gt_left gt_striped" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left gt_striped" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left gt_striped" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> </tr> <tr> <td class="gt_row gt_left" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> </tr> <tr> <td class="gt_row gt_left gt_striped" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left gt_striped" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left gt_striped" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> </tr> <tr> <td class="gt_row gt_left" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> </tr> <tr> <td class="gt_row gt_left gt_striped" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left gt_striped" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left gt_striped" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> </tr> <tr> <td class="gt_row gt_left" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> </tr> <tr> <td class="gt_row gt_left gt_striped" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left gt_striped" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left gt_striped" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> </tr> <tr> <td class="gt_row gt_left" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> </tr> <tr> <td class="gt_row gt_left gt_striped" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left gt_striped" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left gt_striped" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> </tr> <tr> <td class="gt_row gt_left" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> </tr> </body> </table></div> ] .right-two-thirds[ .pull-left[ <style>html { font-family: -apple-system, BlinkMacSystemFont, 'Segoe UI', Roboto, Oxygen, Ubuntu, Cantarell, 'Helvetica Neue', 'Fira Sans', 'Droid Sans', Arial, sans-serif; } #jdzyadnxbs .gt_table { display: table; border-collapse: collapse; margin-left: auto; margin-right: auto; color: #333333; font-size: 16px; background-color: #FFFFFF; /* table.background.color */ width: auto; /* table.width */ border-top-style: solid; /* table.border.top.style */ border-top-width: 2px; /* table.border.top.width */ border-top-color: #A8A8A8; /* table.border.top.color */ border-bottom-style: solid; /* table.border.bottom.style */ border-bottom-width: 2px; /* table.border.bottom.width */ border-bottom-color: #A8A8A8; /* table.border.bottom.color */ } #jdzyadnxbs .gt_heading { background-color: #FFFFFF; /* heading.background.color */ border-bottom-color: #FFFFFF; } #jdzyadnxbs .gt_title { color: #333333; font-size: 125%; /* heading.title.font.size */ padding-top: 4px; /* heading.top.padding - not yet used */ padding-bottom: 4px; border-bottom-color: #FFFFFF; border-bottom-width: 0; } #jdzyadnxbs .gt_subtitle { color: #333333; font-size: 85%; /* heading.subtitle.font.size */ padding-top: 0; padding-bottom: 4px; /* heading.bottom.padding - not yet used */ border-top-color: #FFFFFF; border-top-width: 0; } #jdzyadnxbs .gt_bottom_border { border-bottom-style: solid; /* heading.border.bottom.style */ border-bottom-width: 2px; /* heading.border.bottom.width */ border-bottom-color: #D3D3D3; /* heading.border.bottom.color */ } #jdzyadnxbs .gt_column_spanner { border-bottom-style: solid; border-bottom-width: 2px; border-bottom-color: #D3D3D3; padding-top: 4px; padding-bottom: 4px; } #jdzyadnxbs .gt_col_heading { color: #333333; background-color: #FFFFFF; /* column_labels.background.color */ font-size: 16px; /* column_labels.font.size */ font-weight: initial; /* column_labels.font.weight */ vertical-align: middle; padding: 5px; margin: 10px; overflow-x: hidden; } #jdzyadnxbs .gt_columns_top_border { border-top-style: solid; border-top-width: 2px; border-top-color: #D3D3D3; } #jdzyadnxbs .gt_columns_bottom_border { border-bottom-style: solid; border-bottom-width: 2px; border-bottom-color: #D3D3D3; } #jdzyadnxbs .gt_sep_right { border-right: 5px solid #FFFFFF; } #jdzyadnxbs .gt_group_heading { padding: 8px; /* row_group.padding */ color: #333333; background-color: #FFFFFF; /* row_group.background.color */ font-size: 16px; /* row_group.font.size */ font-weight: initial; /* row_group.font.weight */ border-top-style: solid; /* row_group.border.top.style */ border-top-width: 2px; /* row_group.border.top.width */ border-top-color: #D3D3D3; /* row_group.border.top.color */ border-bottom-style: solid; /* row_group.border.bottom.style */ border-bottom-width: 2px; /* row_group.border.bottom.width */ border-bottom-color: #D3D3D3; /* row_group.border.bottom.color */ vertical-align: middle; } #jdzyadnxbs .gt_empty_group_heading { padding: 0.5px; color: #333333; background-color: #FFFFFF; /* row_group.background.color */ font-size: 16px; /* row_group.font.size */ font-weight: initial; /* row_group.font.weight */ border-top-style: solid; /* row_group.border.top.style */ border-top-width: 2px; /* row_group.border.top.width */ border-top-color: #D3D3D3; /* row_group.border.top.color */ border-bottom-style: solid; /* row_group.border.bottom.style */ border-bottom-width: 2px; /* row_group.border.bottom.width */ border-bottom-color: #D3D3D3; /* row_group.border.bottom.color */ vertical-align: middle; } #jdzyadnxbs .gt_striped { background-color: #8080800D; } #jdzyadnxbs .gt_from_md > :first-child { margin-top: 0; } #jdzyadnxbs .gt_from_md > :last-child { margin-bottom: 0; } #jdzyadnxbs .gt_row { padding: 8px; /* row.padding */ margin: 10px; border-top-style: solid; border-top-width: 1px; border-top-color: #D3D3D3; vertical-align: middle; overflow-x: hidden; } #jdzyadnxbs .gt_stub { border-right-style: solid; border-right-width: 2px; border-right-color: #D3D3D3; padding-left: 12px; } #jdzyadnxbs .gt_summary_row { color: #333333; background-color: #FFFFFF; /* summary_row.background.color */ padding: 8px; /* summary_row.padding */ text-transform: inherit; /* summary_row.text_transform */ } #jdzyadnxbs .gt_grand_summary_row { color: #333333; background-color: #FFFFFF; /* grand_summary_row.background.color */ padding: 8px; /* grand_summary_row.padding */ text-transform: inherit; /* grand_summary_row.text_transform */ } #jdzyadnxbs .gt_first_summary_row { border-top-style: solid; border-top-width: 2px; border-top-color: #D3D3D3; } #jdzyadnxbs .gt_first_grand_summary_row { border-top-style: double; border-top-width: 6px; border-top-color: #D3D3D3; } #jdzyadnxbs .gt_table_body { border-top-style: solid; /* table_body.border.top.style */ border-top-width: 2px; /* table_body.border.top.width */ border-top-color: #D3D3D3; /* table_body.border.top.color */ border-bottom-style: solid; /* table_body.border.bottom.style */ border-bottom-width: 2px; /* table_body.border.bottom.width */ border-bottom-color: #D3D3D3; /* table_body.border.bottom.color */ } #jdzyadnxbs .gt_footnotes { border-top-style: solid; /* footnotes.border.top.style */ border-top-width: 2px; /* footnotes.border.top.width */ border-top-color: #D3D3D3; /* footnotes.border.top.color */ } #jdzyadnxbs .gt_footnote { font-size: 90%; /* footnote.font.size */ margin: 0px; padding: 4px; /* footnote.padding */ } #jdzyadnxbs .gt_sourcenotes { border-top-style: solid; /* sourcenotes.border.top.style */ border-top-width: 2px; /* sourcenotes.border.top.width */ border-top-color: #D3D3D3; /* sourcenotes.border.top.color */ } #jdzyadnxbs .gt_sourcenote { font-size: 90%; /* sourcenote.font.size */ padding: 4px; /* sourcenote.padding */ } #jdzyadnxbs .gt_center { text-align: center; } #jdzyadnxbs .gt_left { text-align: left; } #jdzyadnxbs .gt_right { text-align: right; font-variant-numeric: tabular-nums; } #jdzyadnxbs .gt_font_normal { font-weight: normal; } #jdzyadnxbs .gt_font_bold { font-weight: bold; } #jdzyadnxbs .gt_font_italic { font-style: italic; } #jdzyadnxbs .gt_super { font-size: 65%; } #jdzyadnxbs .gt_footnote_marks { font-style: italic; font-size: 65%; } </style> <div id="jdzyadnxbs" style="overflow-x:auto;overflow-y:auto;width:auto;height:auto;"><table class="gt_table" style="table-layout: fixed; width: 180px"> <colgroup> <col style="width: 60px"/> <col style="width: 60px"/> <col style="width: 60px"/> </colgroup> <tr> <th class="gt_col_heading gt_columns_bottom_border gt_columns_top_border gt_left" rowspan="1" colspan="1"> </th> <th class="gt_col_heading gt_columns_bottom_border gt_columns_top_border gt_left" rowspan="1" colspan="1"> </th> <th class="gt_col_heading gt_columns_bottom_border gt_columns_top_border gt_left" rowspan="1" colspan="1"> </th> </tr> <body class="gt_table_body"> <tr> <td class="gt_row gt_left" style="background-color: #9ACD32FF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left" style="background-color: #9ACD32FF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left" style="background-color: #9ACD32FF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> </tr> <tr> <td class="gt_row gt_left gt_striped" style="background-color: #436EEEFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left gt_striped" style="background-color: #436EEEFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left gt_striped" style="background-color: #436EEEFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> </tr> <tr> <td class="gt_row gt_left" style="background-color: #3A5FCDFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left" style="background-color: #3A5FCDFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left" style="background-color: #3A5FCDFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> </tr> <tr> <td class="gt_row gt_left gt_striped" style="background-color: #00F5FFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left gt_striped" style="background-color: #00F5FFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left gt_striped" style="background-color: #00F5FFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> </tr> <tr> <td class="gt_row gt_left" style="background-color: #B3EE3AFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left" style="background-color: #B3EE3AFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left" style="background-color: #B3EE3AFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> </tr> <tr> <td class="gt_row gt_left gt_striped" style="background-color: #00E5EEFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left gt_striped" style="background-color: #00E5EEFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left gt_striped" style="background-color: #00E5EEFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> </tr> <tr> <td class="gt_row gt_left" style="background-color: #00E5EEFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left" style="background-color: #00E5EEFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left" style="background-color: #00E5EEFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> </tr> <tr> <td class="gt_row gt_left gt_striped" style="background-color: #C0FF3EFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left gt_striped" style="background-color: #C0FF3EFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left gt_striped" style="background-color: #C0FF3EFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> </tr> <tr> <td class="gt_row gt_left" style="background-color: #3A5FCDFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left" style="background-color: #3A5FCDFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left" style="background-color: #3A5FCDFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> </tr> <tr> <td class="gt_row gt_left gt_striped" style="background-color: #9ACD32FF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left gt_striped" style="background-color: #9ACD32FF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left gt_striped" style="background-color: #9ACD32FF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> </tr> <tr> <td class="gt_row gt_left" style="background-color: #00C5CDFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left" style="background-color: #00C5CDFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left" style="background-color: #00C5CDFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> </tr> <tr> <td class="gt_row gt_left gt_striped" style="background-color: #B3EE3AFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left gt_striped" style="background-color: #B3EE3AFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left gt_striped" style="background-color: #B3EE3AFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> </tr> <tr> <td class="gt_row gt_left" style="background-color: #436EEEFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left" style="background-color: #436EEEFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left" style="background-color: #436EEEFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> </tr> <tr> <td class="gt_row gt_left gt_striped" style="background-color: #4876FFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left gt_striped" style="background-color: #4876FFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left gt_striped" style="background-color: #4876FFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> </tr> <tr> <td class="gt_row gt_left" style="background-color: #00C5CDFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left" style="background-color: #00C5CDFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left" style="background-color: #00C5CDFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> </tr> </body> </table></div> ] .pull-right[ <style>html { font-family: -apple-system, BlinkMacSystemFont, 'Segoe UI', Roboto, Oxygen, Ubuntu, Cantarell, 'Helvetica Neue', 'Fira Sans', 'Droid Sans', Arial, sans-serif; } #cjbpwbgqug .gt_table { display: table; border-collapse: collapse; margin-left: auto; margin-right: auto; color: #333333; font-size: 16px; background-color: #FFFFFF; /* table.background.color */ width: auto; /* table.width */ border-top-style: solid; /* table.border.top.style */ border-top-width: 2px; /* table.border.top.width */ border-top-color: #A8A8A8; /* table.border.top.color */ border-bottom-style: solid; /* table.border.bottom.style */ border-bottom-width: 2px; /* table.border.bottom.width */ border-bottom-color: #A8A8A8; /* table.border.bottom.color */ } #cjbpwbgqug .gt_heading { background-color: #FFFFFF; /* heading.background.color */ border-bottom-color: #FFFFFF; } #cjbpwbgqug .gt_title { color: #333333; font-size: 125%; /* heading.title.font.size */ padding-top: 4px; /* heading.top.padding - not yet used */ padding-bottom: 4px; border-bottom-color: #FFFFFF; border-bottom-width: 0; } #cjbpwbgqug .gt_subtitle { color: #333333; font-size: 85%; /* heading.subtitle.font.size */ padding-top: 0; padding-bottom: 4px; /* heading.bottom.padding - not yet used */ border-top-color: #FFFFFF; border-top-width: 0; } #cjbpwbgqug .gt_bottom_border { border-bottom-style: solid; /* heading.border.bottom.style */ border-bottom-width: 2px; /* heading.border.bottom.width */ border-bottom-color: #D3D3D3; /* heading.border.bottom.color */ } #cjbpwbgqug .gt_column_spanner { border-bottom-style: solid; border-bottom-width: 2px; border-bottom-color: #D3D3D3; padding-top: 4px; padding-bottom: 4px; } #cjbpwbgqug .gt_col_heading { color: #333333; background-color: #FFFFFF; /* column_labels.background.color */ font-size: 16px; /* column_labels.font.size */ font-weight: initial; /* column_labels.font.weight */ vertical-align: middle; padding: 5px; margin: 10px; overflow-x: hidden; } #cjbpwbgqug .gt_columns_top_border { border-top-style: solid; border-top-width: 2px; border-top-color: #D3D3D3; } #cjbpwbgqug .gt_columns_bottom_border { border-bottom-style: solid; border-bottom-width: 2px; border-bottom-color: #D3D3D3; } #cjbpwbgqug .gt_sep_right { border-right: 5px solid #FFFFFF; } #cjbpwbgqug .gt_group_heading { padding: 8px; /* row_group.padding */ color: #333333; background-color: #FFFFFF; /* row_group.background.color */ font-size: 16px; /* row_group.font.size */ font-weight: initial; /* row_group.font.weight */ border-top-style: solid; /* row_group.border.top.style */ border-top-width: 2px; /* row_group.border.top.width */ border-top-color: #D3D3D3; /* row_group.border.top.color */ border-bottom-style: solid; /* row_group.border.bottom.style */ border-bottom-width: 2px; /* row_group.border.bottom.width */ border-bottom-color: #D3D3D3; /* row_group.border.bottom.color */ vertical-align: middle; } #cjbpwbgqug .gt_empty_group_heading { padding: 0.5px; color: #333333; background-color: #FFFFFF; /* row_group.background.color */ font-size: 16px; /* row_group.font.size */ font-weight: initial; /* row_group.font.weight */ border-top-style: solid; /* row_group.border.top.style */ border-top-width: 2px; /* row_group.border.top.width */ border-top-color: #D3D3D3; /* row_group.border.top.color */ border-bottom-style: solid; /* row_group.border.bottom.style */ border-bottom-width: 2px; /* row_group.border.bottom.width */ border-bottom-color: #D3D3D3; /* row_group.border.bottom.color */ vertical-align: middle; } #cjbpwbgqug .gt_striped { background-color: #8080800D; } #cjbpwbgqug .gt_from_md > :first-child { margin-top: 0; } #cjbpwbgqug .gt_from_md > :last-child { margin-bottom: 0; } #cjbpwbgqug .gt_row { padding: 8px; /* row.padding */ margin: 10px; border-top-style: solid; border-top-width: 1px; border-top-color: #D3D3D3; vertical-align: middle; overflow-x: hidden; } #cjbpwbgqug .gt_stub { border-right-style: solid; border-right-width: 2px; border-right-color: #D3D3D3; padding-left: 12px; } #cjbpwbgqug .gt_summary_row { color: #333333; background-color: #FFFFFF; /* summary_row.background.color */ padding: 8px; /* summary_row.padding */ text-transform: inherit; /* summary_row.text_transform */ } #cjbpwbgqug .gt_grand_summary_row { color: #333333; background-color: #FFFFFF; /* grand_summary_row.background.color */ padding: 8px; /* grand_summary_row.padding */ text-transform: inherit; /* grand_summary_row.text_transform */ } #cjbpwbgqug .gt_first_summary_row { border-top-style: solid; border-top-width: 2px; border-top-color: #D3D3D3; } #cjbpwbgqug .gt_first_grand_summary_row { border-top-style: double; border-top-width: 6px; border-top-color: #D3D3D3; } #cjbpwbgqug .gt_table_body { border-top-style: solid; /* table_body.border.top.style */ border-top-width: 2px; /* table_body.border.top.width */ border-top-color: #D3D3D3; /* table_body.border.top.color */ border-bottom-style: solid; /* table_body.border.bottom.style */ border-bottom-width: 2px; /* table_body.border.bottom.width */ border-bottom-color: #D3D3D3; /* table_body.border.bottom.color */ } #cjbpwbgqug .gt_footnotes { border-top-style: solid; /* footnotes.border.top.style */ border-top-width: 2px; /* footnotes.border.top.width */ border-top-color: #D3D3D3; /* footnotes.border.top.color */ } #cjbpwbgqug .gt_footnote { font-size: 90%; /* footnote.font.size */ margin: 0px; padding: 4px; /* footnote.padding */ } #cjbpwbgqug .gt_sourcenotes { border-top-style: solid; /* sourcenotes.border.top.style */ border-top-width: 2px; /* sourcenotes.border.top.width */ border-top-color: #D3D3D3; /* sourcenotes.border.top.color */ } #cjbpwbgqug .gt_sourcenote { font-size: 90%; /* sourcenote.font.size */ padding: 4px; /* sourcenote.padding */ } #cjbpwbgqug .gt_center { text-align: center; } #cjbpwbgqug .gt_left { text-align: left; } #cjbpwbgqug .gt_right { text-align: right; font-variant-numeric: tabular-nums; } #cjbpwbgqug .gt_font_normal { font-weight: normal; } #cjbpwbgqug .gt_font_bold { font-weight: bold; } #cjbpwbgqug .gt_font_italic { font-style: italic; } #cjbpwbgqug .gt_super { font-size: 65%; } #cjbpwbgqug .gt_footnote_marks { font-style: italic; font-size: 65%; } </style> <div id="cjbpwbgqug" style="overflow-x:auto;overflow-y:auto;width:auto;height:auto;"><table class="gt_table" style="table-layout: fixed; width: 180px"> <colgroup> <col style="width: 60px"/> <col style="width: 60px"/> <col style="width: 60px"/> </colgroup> <tr> <th class="gt_col_heading gt_columns_bottom_border gt_columns_top_border gt_left" rowspan="1" colspan="1"> </th> <th class="gt_col_heading gt_columns_bottom_border gt_columns_top_border gt_left" rowspan="1" colspan="1"> </th> <th class="gt_col_heading gt_columns_bottom_border gt_columns_top_border gt_left" rowspan="1" colspan="1"> </th> </tr> <body class="gt_table_body"> <tr> <td class="gt_row gt_left" style="background-color: #C0FF3EFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left" style="background-color: #C0FF3EFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left" style="background-color: #C0FF3EFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> </tr> <tr> <td class="gt_row gt_left gt_striped" style="background-color: #B3EE3AFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left gt_striped" style="background-color: #B3EE3AFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left gt_striped" style="background-color: #B3EE3AFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> </tr> <tr> <td class="gt_row gt_left" style="background-color: #B3EE3AFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left" style="background-color: #B3EE3AFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left" style="background-color: #B3EE3AFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> </tr> <tr> <td class="gt_row gt_left gt_striped" style="background-color: #9ACD32FF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left gt_striped" style="background-color: #9ACD32FF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left gt_striped" style="background-color: #9ACD32FF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> </tr> <tr> <td class="gt_row gt_left" style="background-color: #9ACD32FF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left" style="background-color: #9ACD32FF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left" style="background-color: #9ACD32FF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> </tr> <tr> <td class="gt_row gt_left gt_striped" style="background-color: #00F5FFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left gt_striped" style="background-color: #00F5FFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left gt_striped" style="background-color: #00F5FFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> </tr> <tr> <td class="gt_row gt_left" style="background-color: #00E5EEFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left" style="background-color: #00E5EEFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left" style="background-color: #00E5EEFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> </tr> <tr> <td class="gt_row gt_left gt_striped" style="background-color: #00E5EEFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left gt_striped" style="background-color: #00E5EEFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left gt_striped" style="background-color: #00E5EEFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> </tr> <tr> <td class="gt_row gt_left" style="background-color: #00C5CDFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left" style="background-color: #00C5CDFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left" style="background-color: #00C5CDFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> </tr> <tr> <td class="gt_row gt_left gt_striped" style="background-color: #00C5CDFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left gt_striped" style="background-color: #00C5CDFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left gt_striped" style="background-color: #00C5CDFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> </tr> <tr> <td class="gt_row gt_left" style="background-color: #4876FFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left" style="background-color: #4876FFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left" style="background-color: #4876FFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> </tr> <tr> <td class="gt_row gt_left gt_striped" style="background-color: #436EEEFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left gt_striped" style="background-color: #436EEEFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left gt_striped" style="background-color: #436EEEFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> </tr> <tr> <td class="gt_row gt_left" style="background-color: #436EEEFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left" style="background-color: #436EEEFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left" style="background-color: #436EEEFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> </tr> <tr> <td class="gt_row gt_left gt_striped" style="background-color: #3A5FCDFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left gt_striped" style="background-color: #3A5FCDFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left gt_striped" style="background-color: #3A5FCDFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> </tr> <tr> <td class="gt_row gt_left" style="background-color: #3A5FCDFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left" style="background-color: #3A5FCDFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left" style="background-color: #3A5FCDFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> </tr> </body> </table></div> ]] --- ## `arrange()` Example ```r fbi %>% arrange(desc(Year), Type, desc(Count)) %>% head() ``` ``` ## State Abb Year Population Type Count Violent.crime ## 1 California CA 2017 39536653 Aggravated.assault 104454 TRUE ## 2 Texas TX 2017 28304596 Aggravated.assault 76089 TRUE ## 3 Florida FL 2017 20984400 Aggravated.assault 58031 TRUE ## 4 New York NY 2017 19849399 Aggravated.assault 43819 TRUE ## 5 Tennessee TN 2017 6715984 Aggravated.assault 32432 TRUE ## 6 Illinois IL 2017 12802023 Aggravated.assault 32060 TRUE ``` --- ## `select()` Select specific variables of a data frame (vertical selection): `select(.data, ...)` specify all variables you want to keep Variables can be selected by index, e.g. `1:5`, by name (don't use quotes), or using a selector function, such as `starts_with()` Negative selection also works, e.g. `-1` (not the first variable) .left-third[ <style>html { font-family: -apple-system, BlinkMacSystemFont, 'Segoe UI', Roboto, Oxygen, Ubuntu, Cantarell, 'Helvetica Neue', 'Fira Sans', 'Droid Sans', Arial, sans-serif; } #vnuclpcnhl .gt_table { display: table; border-collapse: collapse; margin-left: auto; margin-right: auto; color: #333333; font-size: 16px; background-color: #FFFFFF; /* table.background.color */ width: auto; /* table.width */ border-top-style: solid; /* table.border.top.style */ border-top-width: 2px; /* table.border.top.width */ border-top-color: #A8A8A8; /* table.border.top.color */ border-bottom-style: solid; /* table.border.bottom.style */ border-bottom-width: 2px; /* table.border.bottom.width */ border-bottom-color: #A8A8A8; /* table.border.bottom.color */ } #vnuclpcnhl .gt_heading { background-color: #FFFFFF; /* heading.background.color */ border-bottom-color: #FFFFFF; } #vnuclpcnhl .gt_title { color: #333333; font-size: 125%; /* heading.title.font.size */ padding-top: 4px; /* heading.top.padding - not yet used */ padding-bottom: 4px; border-bottom-color: #FFFFFF; border-bottom-width: 0; } #vnuclpcnhl .gt_subtitle { color: #333333; font-size: 85%; /* heading.subtitle.font.size */ padding-top: 0; padding-bottom: 4px; /* heading.bottom.padding - not yet used */ border-top-color: #FFFFFF; border-top-width: 0; } #vnuclpcnhl .gt_bottom_border { border-bottom-style: solid; /* heading.border.bottom.style */ border-bottom-width: 2px; /* heading.border.bottom.width */ border-bottom-color: #D3D3D3; /* heading.border.bottom.color */ } #vnuclpcnhl .gt_column_spanner { border-bottom-style: solid; border-bottom-width: 2px; border-bottom-color: #D3D3D3; padding-top: 4px; padding-bottom: 4px; } #vnuclpcnhl .gt_col_heading { color: #333333; background-color: #FFFFFF; /* column_labels.background.color */ font-size: 16px; /* column_labels.font.size */ font-weight: initial; /* column_labels.font.weight */ vertical-align: middle; padding: 5px; margin: 10px; overflow-x: hidden; } #vnuclpcnhl .gt_columns_top_border { border-top-style: solid; border-top-width: 2px; border-top-color: #D3D3D3; } #vnuclpcnhl .gt_columns_bottom_border { border-bottom-style: solid; border-bottom-width: 2px; border-bottom-color: #D3D3D3; } #vnuclpcnhl .gt_sep_right { border-right: 5px solid #FFFFFF; } #vnuclpcnhl .gt_group_heading { padding: 8px; /* row_group.padding */ color: #333333; background-color: #FFFFFF; /* row_group.background.color */ font-size: 16px; /* row_group.font.size */ font-weight: initial; /* row_group.font.weight */ border-top-style: solid; /* row_group.border.top.style */ border-top-width: 2px; /* row_group.border.top.width */ border-top-color: #D3D3D3; /* row_group.border.top.color */ border-bottom-style: solid; /* row_group.border.bottom.style */ border-bottom-width: 2px; /* row_group.border.bottom.width */ border-bottom-color: #D3D3D3; /* row_group.border.bottom.color */ vertical-align: middle; } #vnuclpcnhl .gt_empty_group_heading { padding: 0.5px; color: #333333; background-color: #FFFFFF; /* row_group.background.color */ font-size: 16px; /* row_group.font.size */ font-weight: initial; /* row_group.font.weight */ border-top-style: solid; /* row_group.border.top.style */ border-top-width: 2px; /* row_group.border.top.width */ border-top-color: #D3D3D3; /* row_group.border.top.color */ border-bottom-style: solid; /* row_group.border.bottom.style */ border-bottom-width: 2px; /* row_group.border.bottom.width */ border-bottom-color: #D3D3D3; /* row_group.border.bottom.color */ vertical-align: middle; } #vnuclpcnhl .gt_striped { background-color: #8080800D; } #vnuclpcnhl .gt_from_md > :first-child { margin-top: 0; } #vnuclpcnhl .gt_from_md > :last-child { margin-bottom: 0; } #vnuclpcnhl .gt_row { padding: 8px; /* row.padding */ margin: 10px; border-top-style: solid; border-top-width: 1px; border-top-color: #D3D3D3; vertical-align: middle; overflow-x: hidden; } #vnuclpcnhl .gt_stub { border-right-style: solid; border-right-width: 2px; border-right-color: #D3D3D3; padding-left: 12px; } #vnuclpcnhl .gt_summary_row { color: #333333; background-color: #FFFFFF; /* summary_row.background.color */ padding: 8px; /* summary_row.padding */ text-transform: inherit; /* summary_row.text_transform */ } #vnuclpcnhl .gt_grand_summary_row { color: #333333; background-color: #FFFFFF; /* grand_summary_row.background.color */ padding: 8px; /* grand_summary_row.padding */ text-transform: inherit; /* grand_summary_row.text_transform */ } #vnuclpcnhl .gt_first_summary_row { border-top-style: solid; border-top-width: 2px; border-top-color: #D3D3D3; } #vnuclpcnhl .gt_first_grand_summary_row { border-top-style: double; border-top-width: 6px; border-top-color: #D3D3D3; } #vnuclpcnhl .gt_table_body { border-top-style: solid; /* table_body.border.top.style */ border-top-width: 2px; /* table_body.border.top.width */ border-top-color: #D3D3D3; /* table_body.border.top.color */ border-bottom-style: solid; /* table_body.border.bottom.style */ border-bottom-width: 2px; /* table_body.border.bottom.width */ border-bottom-color: #D3D3D3; /* table_body.border.bottom.color */ } #vnuclpcnhl .gt_footnotes { border-top-style: solid; /* footnotes.border.top.style */ border-top-width: 2px; /* footnotes.border.top.width */ border-top-color: #D3D3D3; /* footnotes.border.top.color */ } #vnuclpcnhl .gt_footnote { font-size: 90%; /* footnote.font.size */ margin: 0px; padding: 4px; /* footnote.padding */ } #vnuclpcnhl .gt_sourcenotes { border-top-style: solid; /* sourcenotes.border.top.style */ border-top-width: 2px; /* sourcenotes.border.top.width */ border-top-color: #D3D3D3; /* sourcenotes.border.top.color */ } #vnuclpcnhl .gt_sourcenote { font-size: 90%; /* sourcenote.font.size */ padding: 4px; /* sourcenote.padding */ } #vnuclpcnhl .gt_center { text-align: center; } #vnuclpcnhl .gt_left { text-align: left; } #vnuclpcnhl .gt_right { text-align: right; font-variant-numeric: tabular-nums; } #vnuclpcnhl .gt_font_normal { font-weight: normal; } #vnuclpcnhl .gt_font_bold { font-weight: bold; } #vnuclpcnhl .gt_font_italic { font-style: italic; } #vnuclpcnhl .gt_super { font-size: 65%; } #vnuclpcnhl .gt_footnote_marks { font-style: italic; font-size: 65%; } </style> <div id="vnuclpcnhl" style="overflow-x:auto;overflow-y:auto;width:auto;height:auto;"><table class="gt_table" style="table-layout: fixed; width: 180px"> <colgroup> <col style="width: 60px"/> <col style="width: 60px"/> <col style="width: 60px"/> </colgroup> <tr> <th class="gt_col_heading gt_columns_bottom_border gt_columns_top_border gt_left" rowspan="1" colspan="1"> </th> <th class="gt_col_heading gt_columns_bottom_border gt_columns_top_border gt_left" rowspan="1" colspan="1"> </th> <th class="gt_col_heading gt_columns_bottom_border gt_columns_top_border gt_left" rowspan="1" colspan="1"> </th> </tr> <body class="gt_table_body"> <tr> <td class="gt_row gt_left" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> </tr> <tr> <td class="gt_row gt_left gt_striped" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left gt_striped" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left gt_striped" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> </tr> <tr> <td class="gt_row gt_left" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> </tr> <tr> <td class="gt_row gt_left gt_striped" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left gt_striped" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left gt_striped" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> </tr> <tr> <td class="gt_row gt_left" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> </tr> <tr> <td class="gt_row gt_left gt_striped" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left gt_striped" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left gt_striped" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> </tr> <tr> <td class="gt_row gt_left" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> </tr> <tr> <td class="gt_row gt_left gt_striped" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left gt_striped" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left gt_striped" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> </tr> <tr> <td class="gt_row gt_left" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> </tr> <tr> <td class="gt_row gt_left gt_striped" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left gt_striped" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left gt_striped" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> </tr> <tr> <td class="gt_row gt_left" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> </tr> <tr> <td class="gt_row gt_left gt_striped" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left gt_striped" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left gt_striped" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> </tr> <tr> <td class="gt_row gt_left" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> </tr> <tr> <td class="gt_row gt_left gt_striped" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left gt_striped" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left gt_striped" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> </tr> <tr> <td class="gt_row gt_left" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> </tr> </body> </table></div> ] .right-two-thirds[ .pull-left[ <style>html { font-family: -apple-system, BlinkMacSystemFont, 'Segoe UI', Roboto, Oxygen, Ubuntu, Cantarell, 'Helvetica Neue', 'Fira Sans', 'Droid Sans', Arial, sans-serif; } #bwhsocargp .gt_table { display: table; border-collapse: collapse; margin-left: auto; margin-right: auto; color: #333333; font-size: 16px; background-color: #FFFFFF; /* table.background.color */ width: auto; /* table.width */ border-top-style: solid; /* table.border.top.style */ border-top-width: 2px; /* table.border.top.width */ border-top-color: #A8A8A8; /* table.border.top.color */ border-bottom-style: solid; /* table.border.bottom.style */ border-bottom-width: 2px; /* table.border.bottom.width */ border-bottom-color: #A8A8A8; /* table.border.bottom.color */ } #bwhsocargp .gt_heading { background-color: #FFFFFF; /* heading.background.color */ border-bottom-color: #FFFFFF; } #bwhsocargp .gt_title { color: #333333; font-size: 125%; /* heading.title.font.size */ padding-top: 4px; /* heading.top.padding - not yet used */ padding-bottom: 4px; border-bottom-color: #FFFFFF; border-bottom-width: 0; } #bwhsocargp .gt_subtitle { color: #333333; font-size: 85%; /* heading.subtitle.font.size */ padding-top: 0; padding-bottom: 4px; /* heading.bottom.padding - not yet used */ border-top-color: #FFFFFF; border-top-width: 0; } #bwhsocargp .gt_bottom_border { border-bottom-style: solid; /* heading.border.bottom.style */ border-bottom-width: 2px; /* heading.border.bottom.width */ border-bottom-color: #D3D3D3; /* heading.border.bottom.color */ } #bwhsocargp .gt_column_spanner { border-bottom-style: solid; border-bottom-width: 2px; border-bottom-color: #D3D3D3; padding-top: 4px; padding-bottom: 4px; } #bwhsocargp .gt_col_heading { color: #333333; background-color: #FFFFFF; /* column_labels.background.color */ font-size: 16px; /* column_labels.font.size */ font-weight: initial; /* column_labels.font.weight */ vertical-align: middle; padding: 5px; margin: 10px; overflow-x: hidden; } #bwhsocargp .gt_columns_top_border { border-top-style: solid; border-top-width: 2px; border-top-color: #D3D3D3; } #bwhsocargp .gt_columns_bottom_border { border-bottom-style: solid; border-bottom-width: 2px; border-bottom-color: #D3D3D3; } #bwhsocargp .gt_sep_right { border-right: 5px solid #FFFFFF; } #bwhsocargp .gt_group_heading { padding: 8px; /* row_group.padding */ color: #333333; background-color: #FFFFFF; /* row_group.background.color */ font-size: 16px; /* row_group.font.size */ font-weight: initial; /* row_group.font.weight */ border-top-style: solid; /* row_group.border.top.style */ border-top-width: 2px; /* row_group.border.top.width */ border-top-color: #D3D3D3; /* row_group.border.top.color */ border-bottom-style: solid; /* row_group.border.bottom.style */ border-bottom-width: 2px; /* row_group.border.bottom.width */ border-bottom-color: #D3D3D3; /* row_group.border.bottom.color */ vertical-align: middle; } #bwhsocargp .gt_empty_group_heading { padding: 0.5px; color: #333333; background-color: #FFFFFF; /* row_group.background.color */ font-size: 16px; /* row_group.font.size */ font-weight: initial; /* row_group.font.weight */ border-top-style: solid; /* row_group.border.top.style */ border-top-width: 2px; /* row_group.border.top.width */ border-top-color: #D3D3D3; /* row_group.border.top.color */ border-bottom-style: solid; /* row_group.border.bottom.style */ border-bottom-width: 2px; /* row_group.border.bottom.width */ border-bottom-color: #D3D3D3; /* row_group.border.bottom.color */ vertical-align: middle; } #bwhsocargp .gt_striped { background-color: #8080800D; } #bwhsocargp .gt_from_md > :first-child { margin-top: 0; } #bwhsocargp .gt_from_md > :last-child { margin-bottom: 0; } #bwhsocargp .gt_row { padding: 8px; /* row.padding */ margin: 10px; border-top-style: solid; border-top-width: 1px; border-top-color: #D3D3D3; vertical-align: middle; overflow-x: hidden; } #bwhsocargp .gt_stub { border-right-style: solid; border-right-width: 2px; border-right-color: #D3D3D3; padding-left: 12px; } #bwhsocargp .gt_summary_row { color: #333333; background-color: #FFFFFF; /* summary_row.background.color */ padding: 8px; /* summary_row.padding */ text-transform: inherit; /* summary_row.text_transform */ } #bwhsocargp .gt_grand_summary_row { color: #333333; background-color: #FFFFFF; /* grand_summary_row.background.color */ padding: 8px; /* grand_summary_row.padding */ text-transform: inherit; /* grand_summary_row.text_transform */ } #bwhsocargp .gt_first_summary_row { border-top-style: solid; border-top-width: 2px; border-top-color: #D3D3D3; } #bwhsocargp .gt_first_grand_summary_row { border-top-style: double; border-top-width: 6px; border-top-color: #D3D3D3; } #bwhsocargp .gt_table_body { border-top-style: solid; /* table_body.border.top.style */ border-top-width: 2px; /* table_body.border.top.width */ border-top-color: #D3D3D3; /* table_body.border.top.color */ border-bottom-style: solid; /* table_body.border.bottom.style */ border-bottom-width: 2px; /* table_body.border.bottom.width */ border-bottom-color: #D3D3D3; /* table_body.border.bottom.color */ } #bwhsocargp .gt_footnotes { border-top-style: solid; /* footnotes.border.top.style */ border-top-width: 2px; /* footnotes.border.top.width */ border-top-color: #D3D3D3; /* footnotes.border.top.color */ } #bwhsocargp .gt_footnote { font-size: 90%; /* footnote.font.size */ margin: 0px; padding: 4px; /* footnote.padding */ } #bwhsocargp .gt_sourcenotes { border-top-style: solid; /* sourcenotes.border.top.style */ border-top-width: 2px; /* sourcenotes.border.top.width */ border-top-color: #D3D3D3; /* sourcenotes.border.top.color */ } #bwhsocargp .gt_sourcenote { font-size: 90%; /* sourcenote.font.size */ padding: 4px; /* sourcenote.padding */ } #bwhsocargp .gt_center { text-align: center; } #bwhsocargp .gt_left { text-align: left; } #bwhsocargp .gt_right { text-align: right; font-variant-numeric: tabular-nums; } #bwhsocargp .gt_font_normal { font-weight: normal; } #bwhsocargp .gt_font_bold { font-weight: bold; } #bwhsocargp .gt_font_italic { font-style: italic; } #bwhsocargp .gt_super { font-size: 65%; } #bwhsocargp .gt_footnote_marks { font-style: italic; font-size: 65%; } </style> <div id="bwhsocargp" style="overflow-x:auto;overflow-y:auto;width:auto;height:auto;"><table class="gt_table" style="table-layout: fixed; width: 180px"> <colgroup> <col style="width: 60px"/> <col style="width: 60px"/> <col style="width: 60px"/> </colgroup> <tr> <th class="gt_col_heading gt_columns_bottom_border gt_columns_top_border gt_left" rowspan="1" colspan="1"> </th> <th class="gt_col_heading gt_columns_bottom_border gt_columns_top_border gt_left" rowspan="1" colspan="1"> </th> <th class="gt_col_heading gt_columns_bottom_border gt_columns_top_border gt_left" rowspan="1" colspan="1"> </th> </tr> <body class="gt_table_body"> <tr> <td class="gt_row gt_left" style="background-color: #9ACD32FF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left" style="background-color: #9ACD32FF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> </tr> <tr> <td class="gt_row gt_left gt_striped" style="background-color: #9ACD32FF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left gt_striped" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left gt_striped" style="background-color: #9ACD32FF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> </tr> <tr> <td class="gt_row gt_left" style="background-color: #9ACD32FF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left" style="background-color: #9ACD32FF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> </tr> <tr> <td class="gt_row gt_left gt_striped" style="background-color: #9ACD32FF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left gt_striped" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left gt_striped" style="background-color: #9ACD32FF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> </tr> <tr> <td class="gt_row gt_left" style="background-color: #9ACD32FF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left" style="background-color: #9ACD32FF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> </tr> <tr> <td class="gt_row gt_left gt_striped" style="background-color: #9ACD32FF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left gt_striped" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left gt_striped" style="background-color: #9ACD32FF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> </tr> <tr> <td class="gt_row gt_left" style="background-color: #9ACD32FF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left" style="background-color: #9ACD32FF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> </tr> <tr> <td class="gt_row gt_left gt_striped" style="background-color: #9ACD32FF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left gt_striped" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left gt_striped" style="background-color: #9ACD32FF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> </tr> <tr> <td class="gt_row gt_left" style="background-color: #9ACD32FF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left" style="background-color: #9ACD32FF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> </tr> <tr> <td class="gt_row gt_left gt_striped" style="background-color: #9ACD32FF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left gt_striped" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left gt_striped" style="background-color: #9ACD32FF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> </tr> <tr> <td class="gt_row gt_left" style="background-color: #9ACD32FF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left" style="background-color: #9ACD32FF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> </tr> <tr> <td class="gt_row gt_left gt_striped" style="background-color: #9ACD32FF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left gt_striped" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left gt_striped" style="background-color: #9ACD32FF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> </tr> <tr> <td class="gt_row gt_left" style="background-color: #9ACD32FF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left" style="background-color: #9ACD32FF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> </tr> <tr> <td class="gt_row gt_left gt_striped" style="background-color: #9ACD32FF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left gt_striped" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left gt_striped" style="background-color: #9ACD32FF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> </tr> <tr> <td class="gt_row gt_left" style="background-color: #9ACD32FF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left" style="background-color: #9ACD32FF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> </tr> </body> </table></div> ] .pull-right[ <style>html { font-family: -apple-system, BlinkMacSystemFont, 'Segoe UI', Roboto, Oxygen, Ubuntu, Cantarell, 'Helvetica Neue', 'Fira Sans', 'Droid Sans', Arial, sans-serif; } #rlsvikijsg .gt_table { display: table; border-collapse: collapse; margin-left: auto; margin-right: auto; color: #333333; font-size: 16px; background-color: #FFFFFF; /* table.background.color */ width: auto; /* table.width */ border-top-style: solid; /* table.border.top.style */ border-top-width: 2px; /* table.border.top.width */ border-top-color: #A8A8A8; /* table.border.top.color */ border-bottom-style: solid; /* table.border.bottom.style */ border-bottom-width: 2px; /* table.border.bottom.width */ border-bottom-color: #A8A8A8; /* table.border.bottom.color */ } #rlsvikijsg .gt_heading { background-color: #FFFFFF; /* heading.background.color */ border-bottom-color: #FFFFFF; } #rlsvikijsg .gt_title { color: #333333; font-size: 125%; /* heading.title.font.size */ padding-top: 4px; /* heading.top.padding - not yet used */ padding-bottom: 4px; border-bottom-color: #FFFFFF; border-bottom-width: 0; } #rlsvikijsg .gt_subtitle { color: #333333; font-size: 85%; /* heading.subtitle.font.size */ padding-top: 0; padding-bottom: 4px; /* heading.bottom.padding - not yet used */ border-top-color: #FFFFFF; border-top-width: 0; } #rlsvikijsg .gt_bottom_border { border-bottom-style: solid; /* heading.border.bottom.style */ border-bottom-width: 2px; /* heading.border.bottom.width */ border-bottom-color: #D3D3D3; /* heading.border.bottom.color */ } #rlsvikijsg .gt_column_spanner { border-bottom-style: solid; border-bottom-width: 2px; border-bottom-color: #D3D3D3; padding-top: 4px; padding-bottom: 4px; } #rlsvikijsg .gt_col_heading { color: #333333; background-color: #FFFFFF; /* column_labels.background.color */ font-size: 16px; /* column_labels.font.size */ font-weight: initial; /* column_labels.font.weight */ vertical-align: middle; padding: 5px; margin: 10px; overflow-x: hidden; } #rlsvikijsg .gt_columns_top_border { border-top-style: solid; border-top-width: 2px; border-top-color: #D3D3D3; } #rlsvikijsg .gt_columns_bottom_border { border-bottom-style: solid; border-bottom-width: 2px; border-bottom-color: #D3D3D3; } #rlsvikijsg .gt_sep_right { border-right: 5px solid #FFFFFF; } #rlsvikijsg .gt_group_heading { padding: 8px; /* row_group.padding */ color: #333333; background-color: #FFFFFF; /* row_group.background.color */ font-size: 16px; /* row_group.font.size */ font-weight: initial; /* row_group.font.weight */ border-top-style: solid; /* row_group.border.top.style */ border-top-width: 2px; /* row_group.border.top.width */ border-top-color: #D3D3D3; /* row_group.border.top.color */ border-bottom-style: solid; /* row_group.border.bottom.style */ border-bottom-width: 2px; /* row_group.border.bottom.width */ border-bottom-color: #D3D3D3; /* row_group.border.bottom.color */ vertical-align: middle; } #rlsvikijsg .gt_empty_group_heading { padding: 0.5px; color: #333333; background-color: #FFFFFF; /* row_group.background.color */ font-size: 16px; /* row_group.font.size */ font-weight: initial; /* row_group.font.weight */ border-top-style: solid; /* row_group.border.top.style */ border-top-width: 2px; /* row_group.border.top.width */ border-top-color: #D3D3D3; /* row_group.border.top.color */ border-bottom-style: solid; /* row_group.border.bottom.style */ border-bottom-width: 2px; /* row_group.border.bottom.width */ border-bottom-color: #D3D3D3; /* row_group.border.bottom.color */ vertical-align: middle; } #rlsvikijsg .gt_striped { background-color: #8080800D; } #rlsvikijsg .gt_from_md > :first-child { margin-top: 0; } #rlsvikijsg .gt_from_md > :last-child { margin-bottom: 0; } #rlsvikijsg .gt_row { padding: 8px; /* row.padding */ margin: 10px; border-top-style: solid; border-top-width: 1px; border-top-color: #D3D3D3; vertical-align: middle; overflow-x: hidden; } #rlsvikijsg .gt_stub { border-right-style: solid; border-right-width: 2px; border-right-color: #D3D3D3; padding-left: 12px; } #rlsvikijsg .gt_summary_row { color: #333333; background-color: #FFFFFF; /* summary_row.background.color */ padding: 8px; /* summary_row.padding */ text-transform: inherit; /* summary_row.text_transform */ } #rlsvikijsg .gt_grand_summary_row { color: #333333; background-color: #FFFFFF; /* grand_summary_row.background.color */ padding: 8px; /* grand_summary_row.padding */ text-transform: inherit; /* grand_summary_row.text_transform */ } #rlsvikijsg .gt_first_summary_row { border-top-style: solid; border-top-width: 2px; border-top-color: #D3D3D3; } #rlsvikijsg .gt_first_grand_summary_row { border-top-style: double; border-top-width: 6px; border-top-color: #D3D3D3; } #rlsvikijsg .gt_table_body { border-top-style: solid; /* table_body.border.top.style */ border-top-width: 2px; /* table_body.border.top.width */ border-top-color: #D3D3D3; /* table_body.border.top.color */ border-bottom-style: solid; /* table_body.border.bottom.style */ border-bottom-width: 2px; /* table_body.border.bottom.width */ border-bottom-color: #D3D3D3; /* table_body.border.bottom.color */ } #rlsvikijsg .gt_footnotes { border-top-style: solid; /* footnotes.border.top.style */ border-top-width: 2px; /* footnotes.border.top.width */ border-top-color: #D3D3D3; /* footnotes.border.top.color */ } #rlsvikijsg .gt_footnote { font-size: 90%; /* footnote.font.size */ margin: 0px; padding: 4px; /* footnote.padding */ } #rlsvikijsg .gt_sourcenotes { border-top-style: solid; /* sourcenotes.border.top.style */ border-top-width: 2px; /* sourcenotes.border.top.width */ border-top-color: #D3D3D3; /* sourcenotes.border.top.color */ } #rlsvikijsg .gt_sourcenote { font-size: 90%; /* sourcenote.font.size */ padding: 4px; /* sourcenote.padding */ } #rlsvikijsg .gt_center { text-align: center; } #rlsvikijsg .gt_left { text-align: left; } #rlsvikijsg .gt_right { text-align: right; font-variant-numeric: tabular-nums; } #rlsvikijsg .gt_font_normal { font-weight: normal; } #rlsvikijsg .gt_font_bold { font-weight: bold; } #rlsvikijsg .gt_font_italic { font-style: italic; } #rlsvikijsg .gt_super { font-size: 65%; } #rlsvikijsg .gt_footnote_marks { font-style: italic; font-size: 65%; } </style> <div id="rlsvikijsg" style="overflow-x:auto;overflow-y:auto;width:auto;height:auto;"><table class="gt_table" style="table-layout: fixed; width: 120px"> <colgroup> <col style="width: 60px"/> <col style="width: 60px"/> </colgroup> <tr> <th class="gt_col_heading gt_columns_bottom_border gt_columns_top_border gt_left" rowspan="1" colspan="1"> </th> <th class="gt_col_heading gt_columns_bottom_border gt_columns_top_border gt_left" rowspan="1" colspan="1"> </th> </tr> <body class="gt_table_body"> <tr> <td class="gt_row gt_left" style="background-color: #9ACD32FF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left" style="background-color: #9ACD32FF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> </tr> <tr> <td class="gt_row gt_left gt_striped" style="background-color: #9ACD32FF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left gt_striped" style="background-color: #9ACD32FF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> </tr> <tr> <td class="gt_row gt_left" style="background-color: #9ACD32FF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left" style="background-color: #9ACD32FF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> </tr> <tr> <td class="gt_row gt_left gt_striped" style="background-color: #9ACD32FF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left gt_striped" style="background-color: #9ACD32FF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> </tr> <tr> <td class="gt_row gt_left" style="background-color: #9ACD32FF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left" style="background-color: #9ACD32FF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> </tr> <tr> <td class="gt_row gt_left gt_striped" style="background-color: #9ACD32FF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left gt_striped" style="background-color: #9ACD32FF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> </tr> <tr> <td class="gt_row gt_left" style="background-color: #9ACD32FF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left" style="background-color: #9ACD32FF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> </tr> <tr> <td class="gt_row gt_left gt_striped" style="background-color: #9ACD32FF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left gt_striped" style="background-color: #9ACD32FF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> </tr> <tr> <td class="gt_row gt_left" style="background-color: #9ACD32FF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left" style="background-color: #9ACD32FF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> </tr> <tr> <td class="gt_row gt_left gt_striped" style="background-color: #9ACD32FF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left gt_striped" style="background-color: #9ACD32FF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> </tr> <tr> <td class="gt_row gt_left" style="background-color: #9ACD32FF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left" style="background-color: #9ACD32FF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> </tr> <tr> <td class="gt_row gt_left gt_striped" style="background-color: #9ACD32FF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left gt_striped" style="background-color: #9ACD32FF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> </tr> <tr> <td class="gt_row gt_left" style="background-color: #9ACD32FF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left" style="background-color: #9ACD32FF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> </tr> <tr> <td class="gt_row gt_left gt_striped" style="background-color: #9ACD32FF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left gt_striped" style="background-color: #9ACD32FF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> </tr> <tr> <td class="gt_row gt_left" style="background-color: #9ACD32FF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left" style="background-color: #9ACD32FF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> </tr> </body> </table></div> ]] --- ## `select()` EXAMPLE Select `Type`, `Count`, `State`, and `Year` from the `fbi` data: ```r fbi %>% arrange(desc(Year), Type, desc(Count)) %>% select(Type, Count, State, Year) %>% head() ``` ``` ## Type Count State Year ## 1 Aggravated.assault 104454 California 2017 ## 2 Aggravated.assault 76089 Texas 2017 ## 3 Aggravated.assault 58031 Florida 2017 ## 4 Aggravated.assault 43819 New York 2017 ## 5 Aggravated.assault 32432 Tennessee 2017 ## 6 Aggravated.assault 32060 Illinois 2017 ``` --- background-image: url(https://github.com/allisonhorst/stats-illustrations/raw/master/rstats-artwork/dplyr_mutate.png) background-size: 400px background-position: 50% 100% ## `mutate()` `mutate(.data, ...)` Introduce new variables into the data set or transform/update old variables multiple variables can be changed/introduced `mutate()` works sequentially: variables introduced become available in following changes --- ## `mutate()` EXAMPLE Introduce a variable Rate into the fbi data: ```r fbi %>% mutate(Rate = Count/Population*70000) %>% head() ``` ``` ## State Abb Year Population Type Count Violent.crime Rate ## 1 Alabama AL 1961 3302000 Murder.and.nonnegligent.Manslaughter 427 TRUE 9.052090 ## 2 Alabama AL 1962 3358000 Murder.and.nonnegligent.Manslaughter 316 TRUE 6.587254 ## 3 Alabama AL 1963 3347000 Murder.and.nonnegligent.Manslaughter 340 TRUE 7.110846 ## 4 Alabama AL 1964 3407000 Murder.and.nonnegligent.Manslaughter 316 TRUE 6.492515 ## 5 Alabama AL 1965 3462000 Murder.and.nonnegligent.Manslaughter 395 TRUE 7.986713 ## 6 Alabama AL 1966 3517000 Murder.and.nonnegligent.Manslaughter 384 TRUE 7.642877 ``` --- ## `summarise()` `summarize(.data, ...)` summarize observations into a (set of) one-number statistic(s): Creates a new dataset with 1 row and one column for each of the summary statistics .pull-left[ <style>html { font-family: -apple-system, BlinkMacSystemFont, 'Segoe UI', Roboto, Oxygen, Ubuntu, Cantarell, 'Helvetica Neue', 'Fira Sans', 'Droid Sans', Arial, sans-serif; } #ymfmjdcsba .gt_table { display: table; border-collapse: collapse; margin-left: auto; margin-right: auto; color: #333333; font-size: 16px; background-color: #FFFFFF; /* table.background.color */ width: auto; /* table.width */ border-top-style: solid; /* table.border.top.style */ border-top-width: 2px; /* table.border.top.width */ border-top-color: #A8A8A8; /* table.border.top.color */ border-bottom-style: solid; /* table.border.bottom.style */ border-bottom-width: 2px; /* table.border.bottom.width */ border-bottom-color: #A8A8A8; /* table.border.bottom.color */ } #ymfmjdcsba .gt_heading { background-color: #FFFFFF; /* heading.background.color */ border-bottom-color: #FFFFFF; } #ymfmjdcsba .gt_title { color: #333333; font-size: 125%; /* heading.title.font.size */ padding-top: 4px; /* heading.top.padding - not yet used */ padding-bottom: 4px; border-bottom-color: #FFFFFF; border-bottom-width: 0; } #ymfmjdcsba .gt_subtitle { color: #333333; font-size: 85%; /* heading.subtitle.font.size */ padding-top: 0; padding-bottom: 4px; /* heading.bottom.padding - not yet used */ border-top-color: #FFFFFF; border-top-width: 0; } #ymfmjdcsba .gt_bottom_border { border-bottom-style: solid; /* heading.border.bottom.style */ border-bottom-width: 2px; /* heading.border.bottom.width */ border-bottom-color: #D3D3D3; /* heading.border.bottom.color */ } #ymfmjdcsba .gt_column_spanner { border-bottom-style: solid; border-bottom-width: 2px; border-bottom-color: #D3D3D3; padding-top: 4px; padding-bottom: 4px; } #ymfmjdcsba .gt_col_heading { color: #333333; background-color: #FFFFFF; /* column_labels.background.color */ font-size: 16px; /* column_labels.font.size */ font-weight: initial; /* column_labels.font.weight */ vertical-align: middle; padding: 5px; margin: 10px; overflow-x: hidden; } #ymfmjdcsba .gt_columns_top_border { border-top-style: solid; border-top-width: 2px; border-top-color: #D3D3D3; } #ymfmjdcsba .gt_columns_bottom_border { border-bottom-style: solid; border-bottom-width: 2px; border-bottom-color: #D3D3D3; } #ymfmjdcsba .gt_sep_right { border-right: 5px solid #FFFFFF; } #ymfmjdcsba .gt_group_heading { padding: 8px; /* row_group.padding */ color: #333333; background-color: #FFFFFF; /* row_group.background.color */ font-size: 16px; /* row_group.font.size */ font-weight: initial; /* row_group.font.weight */ border-top-style: solid; /* row_group.border.top.style */ border-top-width: 2px; /* row_group.border.top.width */ border-top-color: #D3D3D3; /* row_group.border.top.color */ border-bottom-style: solid; /* row_group.border.bottom.style */ border-bottom-width: 2px; /* row_group.border.bottom.width */ border-bottom-color: #D3D3D3; /* row_group.border.bottom.color */ vertical-align: middle; } #ymfmjdcsba .gt_empty_group_heading { padding: 0.5px; color: #333333; background-color: #FFFFFF; /* row_group.background.color */ font-size: 16px; /* row_group.font.size */ font-weight: initial; /* row_group.font.weight */ border-top-style: solid; /* row_group.border.top.style */ border-top-width: 2px; /* row_group.border.top.width */ border-top-color: #D3D3D3; /* row_group.border.top.color */ border-bottom-style: solid; /* row_group.border.bottom.style */ border-bottom-width: 2px; /* row_group.border.bottom.width */ border-bottom-color: #D3D3D3; /* row_group.border.bottom.color */ vertical-align: middle; } #ymfmjdcsba .gt_striped { background-color: #8080800D; } #ymfmjdcsba .gt_from_md > :first-child { margin-top: 0; } #ymfmjdcsba .gt_from_md > :last-child { margin-bottom: 0; } #ymfmjdcsba .gt_row { padding: 8px; /* row.padding */ margin: 10px; border-top-style: solid; border-top-width: 1px; border-top-color: #D3D3D3; vertical-align: middle; overflow-x: hidden; } #ymfmjdcsba .gt_stub { border-right-style: solid; border-right-width: 2px; border-right-color: #D3D3D3; padding-left: 12px; } #ymfmjdcsba .gt_summary_row { color: #333333; background-color: #FFFFFF; /* summary_row.background.color */ padding: 8px; /* summary_row.padding */ text-transform: inherit; /* summary_row.text_transform */ } #ymfmjdcsba .gt_grand_summary_row { color: #333333; background-color: #FFFFFF; /* grand_summary_row.background.color */ padding: 8px; /* grand_summary_row.padding */ text-transform: inherit; /* grand_summary_row.text_transform */ } #ymfmjdcsba .gt_first_summary_row { border-top-style: solid; border-top-width: 2px; border-top-color: #D3D3D3; } #ymfmjdcsba .gt_first_grand_summary_row { border-top-style: double; border-top-width: 6px; border-top-color: #D3D3D3; } #ymfmjdcsba .gt_table_body { border-top-style: solid; /* table_body.border.top.style */ border-top-width: 2px; /* table_body.border.top.width */ border-top-color: #D3D3D3; /* table_body.border.top.color */ border-bottom-style: solid; /* table_body.border.bottom.style */ border-bottom-width: 2px; /* table_body.border.bottom.width */ border-bottom-color: #D3D3D3; /* table_body.border.bottom.color */ } #ymfmjdcsba .gt_footnotes { border-top-style: solid; /* footnotes.border.top.style */ border-top-width: 2px; /* footnotes.border.top.width */ border-top-color: #D3D3D3; /* footnotes.border.top.color */ } #ymfmjdcsba .gt_footnote { font-size: 90%; /* footnote.font.size */ margin: 0px; padding: 4px; /* footnote.padding */ } #ymfmjdcsba .gt_sourcenotes { border-top-style: solid; /* sourcenotes.border.top.style */ border-top-width: 2px; /* sourcenotes.border.top.width */ border-top-color: #D3D3D3; /* sourcenotes.border.top.color */ } #ymfmjdcsba .gt_sourcenote { font-size: 90%; /* sourcenote.font.size */ padding: 4px; /* sourcenote.padding */ } #ymfmjdcsba .gt_center { text-align: center; } #ymfmjdcsba .gt_left { text-align: left; } #ymfmjdcsba .gt_right { text-align: right; font-variant-numeric: tabular-nums; } #ymfmjdcsba .gt_font_normal { font-weight: normal; } #ymfmjdcsba .gt_font_bold { font-weight: bold; } #ymfmjdcsba .gt_font_italic { font-style: italic; } #ymfmjdcsba .gt_super { font-size: 65%; } #ymfmjdcsba .gt_footnote_marks { font-style: italic; font-size: 65%; } </style> <div id="ymfmjdcsba" style="overflow-x:auto;overflow-y:auto;width:auto;height:auto;"><table class="gt_table" style="table-layout: fixed; width: 180px"> <colgroup> <col style="width: 60px"/> <col style="width: 60px"/> <col style="width: 60px"/> </colgroup> <tr> <th class="gt_col_heading gt_columns_bottom_border gt_columns_top_border gt_left" rowspan="1" colspan="1"> </th> <th class="gt_col_heading gt_columns_bottom_border gt_columns_top_border gt_left" rowspan="1" colspan="1"> </th> <th class="gt_col_heading gt_columns_bottom_border gt_columns_top_border gt_left" rowspan="1" colspan="1"> </th> </tr> <body class="gt_table_body"> <tr> <td class="gt_row gt_left" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> </tr> <tr> <td class="gt_row gt_left gt_striped" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left gt_striped" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left gt_striped" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> </tr> <tr> <td class="gt_row gt_left" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> </tr> <tr> <td class="gt_row gt_left gt_striped" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left gt_striped" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left gt_striped" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> </tr> <tr> <td class="gt_row gt_left" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> </tr> <tr> <td class="gt_row gt_left gt_striped" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left gt_striped" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left gt_striped" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> </tr> <tr> <td class="gt_row gt_left" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> </tr> <tr> <td class="gt_row gt_left gt_striped" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left gt_striped" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left gt_striped" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> </tr> <tr> <td class="gt_row gt_left" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> </tr> <tr> <td class="gt_row gt_left gt_striped" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left gt_striped" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left gt_striped" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> </tr> <tr> <td class="gt_row gt_left" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> </tr> <tr> <td class="gt_row gt_left gt_striped" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left gt_striped" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left gt_striped" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> </tr> <tr> <td class="gt_row gt_left" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> </tr> <tr> <td class="gt_row gt_left gt_striped" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left gt_striped" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left gt_striped" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> </tr> <tr> <td class="gt_row gt_left" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> </tr> </body> </table></div> ] .pull-left[ <style>html { font-family: -apple-system, BlinkMacSystemFont, 'Segoe UI', Roboto, Oxygen, Ubuntu, Cantarell, 'Helvetica Neue', 'Fira Sans', 'Droid Sans', Arial, sans-serif; } #njpbjyxlmo .gt_table { display: table; border-collapse: collapse; margin-left: auto; margin-right: auto; color: #333333; font-size: 16px; background-color: #FFFFFF; /* table.background.color */ width: auto; /* table.width */ border-top-style: solid; /* table.border.top.style */ border-top-width: 2px; /* table.border.top.width */ border-top-color: #A8A8A8; /* table.border.top.color */ border-bottom-style: solid; /* table.border.bottom.style */ border-bottom-width: 2px; /* table.border.bottom.width */ border-bottom-color: #A8A8A8; /* table.border.bottom.color */ } #njpbjyxlmo .gt_heading { background-color: #FFFFFF; /* heading.background.color */ border-bottom-color: #FFFFFF; } #njpbjyxlmo .gt_title { color: #333333; font-size: 125%; /* heading.title.font.size */ padding-top: 4px; /* heading.top.padding - not yet used */ padding-bottom: 4px; border-bottom-color: #FFFFFF; border-bottom-width: 0; } #njpbjyxlmo .gt_subtitle { color: #333333; font-size: 85%; /* heading.subtitle.font.size */ padding-top: 0; padding-bottom: 4px; /* heading.bottom.padding - not yet used */ border-top-color: #FFFFFF; border-top-width: 0; } #njpbjyxlmo .gt_bottom_border { border-bottom-style: solid; /* heading.border.bottom.style */ border-bottom-width: 2px; /* heading.border.bottom.width */ border-bottom-color: #D3D3D3; /* heading.border.bottom.color */ } #njpbjyxlmo .gt_column_spanner { border-bottom-style: solid; border-bottom-width: 2px; border-bottom-color: #D3D3D3; padding-top: 4px; padding-bottom: 4px; } #njpbjyxlmo .gt_col_heading { color: #333333; background-color: #FFFFFF; /* column_labels.background.color */ font-size: 16px; /* column_labels.font.size */ font-weight: initial; /* column_labels.font.weight */ vertical-align: middle; padding: 5px; margin: 10px; overflow-x: hidden; } #njpbjyxlmo .gt_columns_top_border { border-top-style: solid; border-top-width: 2px; border-top-color: #D3D3D3; } #njpbjyxlmo .gt_columns_bottom_border { border-bottom-style: solid; border-bottom-width: 2px; border-bottom-color: #D3D3D3; } #njpbjyxlmo .gt_sep_right { border-right: 5px solid #FFFFFF; } #njpbjyxlmo .gt_group_heading { padding: 8px; /* row_group.padding */ color: #333333; background-color: #FFFFFF; /* row_group.background.color */ font-size: 16px; /* row_group.font.size */ font-weight: initial; /* row_group.font.weight */ border-top-style: solid; /* row_group.border.top.style */ border-top-width: 2px; /* row_group.border.top.width */ border-top-color: #D3D3D3; /* row_group.border.top.color */ border-bottom-style: solid; /* row_group.border.bottom.style */ border-bottom-width: 2px; /* row_group.border.bottom.width */ border-bottom-color: #D3D3D3; /* row_group.border.bottom.color */ vertical-align: middle; } #njpbjyxlmo .gt_empty_group_heading { padding: 0.5px; color: #333333; background-color: #FFFFFF; /* row_group.background.color */ font-size: 16px; /* row_group.font.size */ font-weight: initial; /* row_group.font.weight */ border-top-style: solid; /* row_group.border.top.style */ border-top-width: 2px; /* row_group.border.top.width */ border-top-color: #D3D3D3; /* row_group.border.top.color */ border-bottom-style: solid; /* row_group.border.bottom.style */ border-bottom-width: 2px; /* row_group.border.bottom.width */ border-bottom-color: #D3D3D3; /* row_group.border.bottom.color */ vertical-align: middle; } #njpbjyxlmo .gt_striped { background-color: #8080800D; } #njpbjyxlmo .gt_from_md > :first-child { margin-top: 0; } #njpbjyxlmo .gt_from_md > :last-child { margin-bottom: 0; } #njpbjyxlmo .gt_row { padding: 8px; /* row.padding */ margin: 10px; border-top-style: solid; border-top-width: 1px; border-top-color: #D3D3D3; vertical-align: middle; overflow-x: hidden; } #njpbjyxlmo .gt_stub { border-right-style: solid; border-right-width: 2px; border-right-color: #D3D3D3; padding-left: 12px; } #njpbjyxlmo .gt_summary_row { color: #333333; background-color: #FFFFFF; /* summary_row.background.color */ padding: 8px; /* summary_row.padding */ text-transform: inherit; /* summary_row.text_transform */ } #njpbjyxlmo .gt_grand_summary_row { color: #333333; background-color: #FFFFFF; /* grand_summary_row.background.color */ padding: 8px; /* grand_summary_row.padding */ text-transform: inherit; /* grand_summary_row.text_transform */ } #njpbjyxlmo .gt_first_summary_row { border-top-style: solid; border-top-width: 2px; border-top-color: #D3D3D3; } #njpbjyxlmo .gt_first_grand_summary_row { border-top-style: double; border-top-width: 6px; border-top-color: #D3D3D3; } #njpbjyxlmo .gt_table_body { border-top-style: solid; /* table_body.border.top.style */ border-top-width: 2px; /* table_body.border.top.width */ border-top-color: #D3D3D3; /* table_body.border.top.color */ border-bottom-style: solid; /* table_body.border.bottom.style */ border-bottom-width: 2px; /* table_body.border.bottom.width */ border-bottom-color: #D3D3D3; /* table_body.border.bottom.color */ } #njpbjyxlmo .gt_footnotes { border-top-style: solid; /* footnotes.border.top.style */ border-top-width: 2px; /* footnotes.border.top.width */ border-top-color: #D3D3D3; /* footnotes.border.top.color */ } #njpbjyxlmo .gt_footnote { font-size: 90%; /* footnote.font.size */ margin: 0px; padding: 4px; /* footnote.padding */ } #njpbjyxlmo .gt_sourcenotes { border-top-style: solid; /* sourcenotes.border.top.style */ border-top-width: 2px; /* sourcenotes.border.top.width */ border-top-color: #D3D3D3; /* sourcenotes.border.top.color */ } #njpbjyxlmo .gt_sourcenote { font-size: 90%; /* sourcenote.font.size */ padding: 4px; /* sourcenote.padding */ } #njpbjyxlmo .gt_center { text-align: center; } #njpbjyxlmo .gt_left { text-align: left; } #njpbjyxlmo .gt_right { text-align: right; font-variant-numeric: tabular-nums; } #njpbjyxlmo .gt_font_normal { font-weight: normal; } #njpbjyxlmo .gt_font_bold { font-weight: bold; } #njpbjyxlmo .gt_font_italic { font-style: italic; } #njpbjyxlmo .gt_super { font-size: 65%; } #njpbjyxlmo .gt_footnote_marks { font-style: italic; font-size: 65%; } </style> <div id="njpbjyxlmo" style="overflow-x:auto;overflow-y:auto;width:auto;height:auto;"><table class="gt_table" style="table-layout: fixed; width: 180px"> <colgroup> <col style="width: 60px"/> <col style="width: 60px"/> <col style="width: 60px"/> </colgroup> <tr> <th class="gt_col_heading gt_columns_bottom_border gt_columns_top_border gt_left" rowspan="1" colspan="1"> </th> <th class="gt_col_heading gt_columns_bottom_border gt_columns_top_border gt_left" rowspan="1" colspan="1"> </th> <th class="gt_col_heading gt_columns_bottom_border gt_columns_top_border gt_left" rowspan="1" colspan="1"> </th> </tr> <body class="gt_table_body"> <tr> <td class="gt_row gt_left" style="background-color: #9ACD32FF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left" style="background-color: #9ACD32FF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left" style="background-color: #9ACD32FF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> </tr> </body> </table></div> ] --- ## `summarise()` EXAMPLE Calculate the mean and standard deviation of Crime rates in the `fbi` data ```r fbi %>% summarise(mean_rate = mean(Count/Population*70000, na.rm=TRUE), sd_rate = sd(Count/Population*70000, na.rm = TRUE)) ``` ``` ## mean_rate sd_rate ## 1 397.9617 612.8635 ``` --- ## `group_by()` & `summarise()` Power combo! for each combination of group levels, create one row of a (set of) one-number statistic(s) The new dataset has one column for each of the summary statistics, and one row for each combination of grouping levels (multiplicative) .left-third[ <style>html { font-family: -apple-system, BlinkMacSystemFont, 'Segoe UI', Roboto, Oxygen, Ubuntu, Cantarell, 'Helvetica Neue', 'Fira Sans', 'Droid Sans', Arial, sans-serif; } #vbftjrwqic .gt_table { display: table; border-collapse: collapse; margin-left: auto; margin-right: auto; color: #333333; font-size: 16px; background-color: #FFFFFF; /* table.background.color */ width: auto; /* table.width */ border-top-style: solid; /* table.border.top.style */ border-top-width: 2px; /* table.border.top.width */ border-top-color: #A8A8A8; /* table.border.top.color */ border-bottom-style: solid; /* table.border.bottom.style */ border-bottom-width: 2px; /* table.border.bottom.width */ border-bottom-color: #A8A8A8; /* table.border.bottom.color */ } #vbftjrwqic .gt_heading { background-color: #FFFFFF; /* heading.background.color */ border-bottom-color: #FFFFFF; } #vbftjrwqic .gt_title { color: #333333; font-size: 125%; /* heading.title.font.size */ padding-top: 4px; /* heading.top.padding - not yet used */ padding-bottom: 4px; border-bottom-color: #FFFFFF; border-bottom-width: 0; } #vbftjrwqic .gt_subtitle { color: #333333; font-size: 85%; /* heading.subtitle.font.size */ padding-top: 0; padding-bottom: 4px; /* heading.bottom.padding - not yet used */ border-top-color: #FFFFFF; border-top-width: 0; } #vbftjrwqic .gt_bottom_border { border-bottom-style: solid; /* heading.border.bottom.style */ border-bottom-width: 2px; /* heading.border.bottom.width */ border-bottom-color: #D3D3D3; /* heading.border.bottom.color */ } #vbftjrwqic .gt_column_spanner { border-bottom-style: solid; border-bottom-width: 2px; border-bottom-color: #D3D3D3; padding-top: 4px; padding-bottom: 4px; } #vbftjrwqic .gt_col_heading { color: #333333; background-color: #FFFFFF; /* column_labels.background.color */ font-size: 16px; /* column_labels.font.size */ font-weight: initial; /* column_labels.font.weight */ vertical-align: middle; padding: 5px; margin: 10px; overflow-x: hidden; } #vbftjrwqic .gt_columns_top_border { border-top-style: solid; border-top-width: 2px; border-top-color: #D3D3D3; } #vbftjrwqic .gt_columns_bottom_border { border-bottom-style: solid; border-bottom-width: 2px; border-bottom-color: #D3D3D3; } #vbftjrwqic .gt_sep_right { border-right: 5px solid #FFFFFF; } #vbftjrwqic .gt_group_heading { padding: 8px; /* row_group.padding */ color: #333333; background-color: #FFFFFF; /* row_group.background.color */ font-size: 16px; /* row_group.font.size */ font-weight: initial; /* row_group.font.weight */ border-top-style: solid; /* row_group.border.top.style */ border-top-width: 2px; /* row_group.border.top.width */ border-top-color: #D3D3D3; /* row_group.border.top.color */ border-bottom-style: solid; /* row_group.border.bottom.style */ border-bottom-width: 2px; /* row_group.border.bottom.width */ border-bottom-color: #D3D3D3; /* row_group.border.bottom.color */ vertical-align: middle; } #vbftjrwqic .gt_empty_group_heading { padding: 0.5px; color: #333333; background-color: #FFFFFF; /* row_group.background.color */ font-size: 16px; /* row_group.font.size */ font-weight: initial; /* row_group.font.weight */ border-top-style: solid; /* row_group.border.top.style */ border-top-width: 2px; /* row_group.border.top.width */ border-top-color: #D3D3D3; /* row_group.border.top.color */ border-bottom-style: solid; /* row_group.border.bottom.style */ border-bottom-width: 2px; /* row_group.border.bottom.width */ border-bottom-color: #D3D3D3; /* row_group.border.bottom.color */ vertical-align: middle; } #vbftjrwqic .gt_striped { background-color: #8080800D; } #vbftjrwqic .gt_from_md > :first-child { margin-top: 0; } #vbftjrwqic .gt_from_md > :last-child { margin-bottom: 0; } #vbftjrwqic .gt_row { padding: 8px; /* row.padding */ margin: 10px; border-top-style: solid; border-top-width: 1px; border-top-color: #D3D3D3; vertical-align: middle; overflow-x: hidden; } #vbftjrwqic .gt_stub { border-right-style: solid; border-right-width: 2px; border-right-color: #D3D3D3; padding-left: 12px; } #vbftjrwqic .gt_summary_row { color: #333333; background-color: #FFFFFF; /* summary_row.background.color */ padding: 8px; /* summary_row.padding */ text-transform: inherit; /* summary_row.text_transform */ } #vbftjrwqic .gt_grand_summary_row { color: #333333; background-color: #FFFFFF; /* grand_summary_row.background.color */ padding: 8px; /* grand_summary_row.padding */ text-transform: inherit; /* grand_summary_row.text_transform */ } #vbftjrwqic .gt_first_summary_row { border-top-style: solid; border-top-width: 2px; border-top-color: #D3D3D3; } #vbftjrwqic .gt_first_grand_summary_row { border-top-style: double; border-top-width: 6px; border-top-color: #D3D3D3; } #vbftjrwqic .gt_table_body { border-top-style: solid; /* table_body.border.top.style */ border-top-width: 2px; /* table_body.border.top.width */ border-top-color: #D3D3D3; /* table_body.border.top.color */ border-bottom-style: solid; /* table_body.border.bottom.style */ border-bottom-width: 2px; /* table_body.border.bottom.width */ border-bottom-color: #D3D3D3; /* table_body.border.bottom.color */ } #vbftjrwqic .gt_footnotes { border-top-style: solid; /* footnotes.border.top.style */ border-top-width: 2px; /* footnotes.border.top.width */ border-top-color: #D3D3D3; /* footnotes.border.top.color */ } #vbftjrwqic .gt_footnote { font-size: 90%; /* footnote.font.size */ margin: 0px; padding: 4px; /* footnote.padding */ } #vbftjrwqic .gt_sourcenotes { border-top-style: solid; /* sourcenotes.border.top.style */ border-top-width: 2px; /* sourcenotes.border.top.width */ border-top-color: #D3D3D3; /* sourcenotes.border.top.color */ } #vbftjrwqic .gt_sourcenote { font-size: 90%; /* sourcenote.font.size */ padding: 4px; /* sourcenote.padding */ } #vbftjrwqic .gt_center { text-align: center; } #vbftjrwqic .gt_left { text-align: left; } #vbftjrwqic .gt_right { text-align: right; font-variant-numeric: tabular-nums; } #vbftjrwqic .gt_font_normal { font-weight: normal; } #vbftjrwqic .gt_font_bold { font-weight: bold; } #vbftjrwqic .gt_font_italic { font-style: italic; } #vbftjrwqic .gt_super { font-size: 65%; } #vbftjrwqic .gt_footnote_marks { font-style: italic; font-size: 65%; } </style> <div id="vbftjrwqic" style="overflow-x:auto;overflow-y:auto;width:auto;height:auto;"><table class="gt_table" style="table-layout: fixed; width: 180px"> <colgroup> <col style="width: 60px"/> <col style="width: 60px"/> <col style="width: 60px"/> </colgroup> <tr> <th class="gt_col_heading gt_columns_bottom_border gt_columns_top_border gt_left" rowspan="1" colspan="1"> </th> <th class="gt_col_heading gt_columns_bottom_border gt_columns_top_border gt_left" rowspan="1" colspan="1"> </th> <th class="gt_col_heading gt_columns_bottom_border gt_columns_top_border gt_left" rowspan="1" colspan="1"> </th> </tr> <body class="gt_table_body"> <tr> <td class="gt_row gt_left" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> </tr> <tr> <td class="gt_row gt_left gt_striped" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left gt_striped" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left gt_striped" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> </tr> <tr> <td class="gt_row gt_left" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> </tr> <tr> <td class="gt_row gt_left gt_striped" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left gt_striped" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left gt_striped" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> </tr> <tr> <td class="gt_row gt_left" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> </tr> <tr> <td class="gt_row gt_left gt_striped" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left gt_striped" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left gt_striped" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> </tr> <tr> <td class="gt_row gt_left" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> </tr> <tr> <td class="gt_row gt_left gt_striped" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left gt_striped" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left gt_striped" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> </tr> <tr> <td class="gt_row gt_left" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> </tr> <tr> <td class="gt_row gt_left gt_striped" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left gt_striped" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left gt_striped" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> </tr> <tr> <td class="gt_row gt_left" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> </tr> <tr> <td class="gt_row gt_left gt_striped" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left gt_striped" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left gt_striped" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> </tr> <tr> <td class="gt_row gt_left" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> </tr> <tr> <td class="gt_row gt_left gt_striped" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left gt_striped" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left gt_striped" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> </tr> <tr> <td class="gt_row gt_left" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left" style="background-color: #FFFFFFFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> </tr> </body> </table></div> ] .right-two-thirds[ .pull-left[ <style>html { font-family: -apple-system, BlinkMacSystemFont, 'Segoe UI', Roboto, Oxygen, Ubuntu, Cantarell, 'Helvetica Neue', 'Fira Sans', 'Droid Sans', Arial, sans-serif; } #nulabpeolm .gt_table { display: table; border-collapse: collapse; margin-left: auto; margin-right: auto; color: #333333; font-size: 16px; background-color: #FFFFFF; /* table.background.color */ width: auto; /* table.width */ border-top-style: solid; /* table.border.top.style */ border-top-width: 2px; /* table.border.top.width */ border-top-color: #A8A8A8; /* table.border.top.color */ border-bottom-style: solid; /* table.border.bottom.style */ border-bottom-width: 2px; /* table.border.bottom.width */ border-bottom-color: #A8A8A8; /* table.border.bottom.color */ } #nulabpeolm .gt_heading { background-color: #FFFFFF; /* heading.background.color */ border-bottom-color: #FFFFFF; } #nulabpeolm .gt_title { color: #333333; font-size: 125%; /* heading.title.font.size */ padding-top: 4px; /* heading.top.padding - not yet used */ padding-bottom: 4px; border-bottom-color: #FFFFFF; border-bottom-width: 0; } #nulabpeolm .gt_subtitle { color: #333333; font-size: 85%; /* heading.subtitle.font.size */ padding-top: 0; padding-bottom: 4px; /* heading.bottom.padding - not yet used */ border-top-color: #FFFFFF; border-top-width: 0; } #nulabpeolm .gt_bottom_border { border-bottom-style: solid; /* heading.border.bottom.style */ border-bottom-width: 2px; /* heading.border.bottom.width */ border-bottom-color: #D3D3D3; /* heading.border.bottom.color */ } #nulabpeolm .gt_column_spanner { border-bottom-style: solid; border-bottom-width: 2px; border-bottom-color: #D3D3D3; padding-top: 4px; padding-bottom: 4px; } #nulabpeolm .gt_col_heading { color: #333333; background-color: #FFFFFF; /* column_labels.background.color */ font-size: 16px; /* column_labels.font.size */ font-weight: initial; /* column_labels.font.weight */ vertical-align: middle; padding: 5px; margin: 10px; overflow-x: hidden; } #nulabpeolm .gt_columns_top_border { border-top-style: solid; border-top-width: 2px; border-top-color: #D3D3D3; } #nulabpeolm .gt_columns_bottom_border { border-bottom-style: solid; border-bottom-width: 2px; border-bottom-color: #D3D3D3; } #nulabpeolm .gt_sep_right { border-right: 5px solid #FFFFFF; } #nulabpeolm .gt_group_heading { padding: 8px; /* row_group.padding */ color: #333333; background-color: #FFFFFF; /* row_group.background.color */ font-size: 16px; /* row_group.font.size */ font-weight: initial; /* row_group.font.weight */ border-top-style: solid; /* row_group.border.top.style */ border-top-width: 2px; /* row_group.border.top.width */ border-top-color: #D3D3D3; /* row_group.border.top.color */ border-bottom-style: solid; /* row_group.border.bottom.style */ border-bottom-width: 2px; /* row_group.border.bottom.width */ border-bottom-color: #D3D3D3; /* row_group.border.bottom.color */ vertical-align: middle; } #nulabpeolm .gt_empty_group_heading { padding: 0.5px; color: #333333; background-color: #FFFFFF; /* row_group.background.color */ font-size: 16px; /* row_group.font.size */ font-weight: initial; /* row_group.font.weight */ border-top-style: solid; /* row_group.border.top.style */ border-top-width: 2px; /* row_group.border.top.width */ border-top-color: #D3D3D3; /* row_group.border.top.color */ border-bottom-style: solid; /* row_group.border.bottom.style */ border-bottom-width: 2px; /* row_group.border.bottom.width */ border-bottom-color: #D3D3D3; /* row_group.border.bottom.color */ vertical-align: middle; } #nulabpeolm .gt_striped { background-color: #8080800D; } #nulabpeolm .gt_from_md > :first-child { margin-top: 0; } #nulabpeolm .gt_from_md > :last-child { margin-bottom: 0; } #nulabpeolm .gt_row { padding: 8px; /* row.padding */ margin: 10px; border-top-style: solid; border-top-width: 1px; border-top-color: #D3D3D3; vertical-align: middle; overflow-x: hidden; } #nulabpeolm .gt_stub { border-right-style: solid; border-right-width: 2px; border-right-color: #D3D3D3; padding-left: 12px; } #nulabpeolm .gt_summary_row { color: #333333; background-color: #FFFFFF; /* summary_row.background.color */ padding: 8px; /* summary_row.padding */ text-transform: inherit; /* summary_row.text_transform */ } #nulabpeolm .gt_grand_summary_row { color: #333333; background-color: #FFFFFF; /* grand_summary_row.background.color */ padding: 8px; /* grand_summary_row.padding */ text-transform: inherit; /* grand_summary_row.text_transform */ } #nulabpeolm .gt_first_summary_row { border-top-style: solid; border-top-width: 2px; border-top-color: #D3D3D3; } #nulabpeolm .gt_first_grand_summary_row { border-top-style: double; border-top-width: 6px; border-top-color: #D3D3D3; } #nulabpeolm .gt_table_body { border-top-style: solid; /* table_body.border.top.style */ border-top-width: 2px; /* table_body.border.top.width */ border-top-color: #D3D3D3; /* table_body.border.top.color */ border-bottom-style: solid; /* table_body.border.bottom.style */ border-bottom-width: 2px; /* table_body.border.bottom.width */ border-bottom-color: #D3D3D3; /* table_body.border.bottom.color */ } #nulabpeolm .gt_footnotes { border-top-style: solid; /* footnotes.border.top.style */ border-top-width: 2px; /* footnotes.border.top.width */ border-top-color: #D3D3D3; /* footnotes.border.top.color */ } #nulabpeolm .gt_footnote { font-size: 90%; /* footnote.font.size */ margin: 0px; padding: 4px; /* footnote.padding */ } #nulabpeolm .gt_sourcenotes { border-top-style: solid; /* sourcenotes.border.top.style */ border-top-width: 2px; /* sourcenotes.border.top.width */ border-top-color: #D3D3D3; /* sourcenotes.border.top.color */ } #nulabpeolm .gt_sourcenote { font-size: 90%; /* sourcenote.font.size */ padding: 4px; /* sourcenote.padding */ } #nulabpeolm .gt_center { text-align: center; } #nulabpeolm .gt_left { text-align: left; } #nulabpeolm .gt_right { text-align: right; font-variant-numeric: tabular-nums; } #nulabpeolm .gt_font_normal { font-weight: normal; } #nulabpeolm .gt_font_bold { font-weight: bold; } #nulabpeolm .gt_font_italic { font-style: italic; } #nulabpeolm .gt_super { font-size: 65%; } #nulabpeolm .gt_footnote_marks { font-style: italic; font-size: 65%; } </style> <div id="nulabpeolm" style="overflow-x:auto;overflow-y:auto;width:auto;height:auto;"><table class="gt_table" style="table-layout: fixed; width: 180px"> <colgroup> <col style="width: 60px"/> <col style="width: 60px"/> <col style="width: 60px"/> </colgroup> <tr> <th class="gt_col_heading gt_columns_bottom_border gt_columns_top_border gt_left" rowspan="1" colspan="1"> </th> <th class="gt_col_heading gt_columns_bottom_border gt_columns_top_border gt_left" rowspan="1" colspan="1"> </th> <th class="gt_col_heading gt_columns_bottom_border gt_columns_top_border gt_left" rowspan="1" colspan="1"> </th> </tr> <body class="gt_table_body"> <tr> <td class="gt_row gt_left" style="background-color: #9ACD32FF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left" style="background-color: #9ACD32FF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left" style="background-color: #9ACD32FF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> </tr> <tr> <td class="gt_row gt_left gt_striped" style="background-color: #3A5FCDFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left gt_striped" style="background-color: #3A5FCDFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left gt_striped" style="background-color: #3A5FCDFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> </tr> <tr> <td class="gt_row gt_left" style="background-color: #3A5FCDFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left" style="background-color: #3A5FCDFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left" style="background-color: #3A5FCDFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> </tr> <tr> <td class="gt_row gt_left gt_striped" style="background-color: #00C5CDFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left gt_striped" style="background-color: #00C5CDFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left gt_striped" style="background-color: #00C5CDFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> </tr> <tr> <td class="gt_row gt_left" style="background-color: #9ACD32FF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left" style="background-color: #9ACD32FF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left" style="background-color: #9ACD32FF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> </tr> <tr> <td class="gt_row gt_left gt_striped" style="background-color: #00C5CDFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left gt_striped" style="background-color: #00C5CDFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left gt_striped" style="background-color: #00C5CDFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> </tr> <tr> <td class="gt_row gt_left" style="background-color: #00C5CDFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left" style="background-color: #00C5CDFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left" style="background-color: #00C5CDFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> </tr> <tr> <td class="gt_row gt_left gt_striped" style="background-color: #9ACD32FF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left gt_striped" style="background-color: #9ACD32FF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left gt_striped" style="background-color: #9ACD32FF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> </tr> <tr> <td class="gt_row gt_left" style="background-color: #3A5FCDFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left" style="background-color: #3A5FCDFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left" style="background-color: #3A5FCDFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> </tr> <tr> <td class="gt_row gt_left gt_striped" style="background-color: #9ACD32FF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left gt_striped" style="background-color: #9ACD32FF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left gt_striped" style="background-color: #9ACD32FF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> </tr> <tr> <td class="gt_row gt_left" style="background-color: #00C5CDFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left" style="background-color: #00C5CDFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left" style="background-color: #00C5CDFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> </tr> <tr> <td class="gt_row gt_left gt_striped" style="background-color: #9ACD32FF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left gt_striped" style="background-color: #9ACD32FF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left gt_striped" style="background-color: #9ACD32FF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> </tr> <tr> <td class="gt_row gt_left" style="background-color: #3A5FCDFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left" style="background-color: #3A5FCDFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left" style="background-color: #3A5FCDFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> </tr> <tr> <td class="gt_row gt_left gt_striped" style="background-color: #3A5FCDFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left gt_striped" style="background-color: #3A5FCDFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left gt_striped" style="background-color: #3A5FCDFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> </tr> <tr> <td class="gt_row gt_left" style="background-color: #00C5CDFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left" style="background-color: #00C5CDFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left" style="background-color: #00C5CDFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> </tr> </body> </table></div> ] .pull-right[ <style>html { font-family: -apple-system, BlinkMacSystemFont, 'Segoe UI', Roboto, Oxygen, Ubuntu, Cantarell, 'Helvetica Neue', 'Fira Sans', 'Droid Sans', Arial, sans-serif; } #sxebjwowzx .gt_table { display: table; border-collapse: collapse; margin-left: auto; margin-right: auto; color: #333333; font-size: 16px; background-color: #FFFFFF; /* table.background.color */ width: auto; /* table.width */ border-top-style: solid; /* table.border.top.style */ border-top-width: 2px; /* table.border.top.width */ border-top-color: #A8A8A8; /* table.border.top.color */ border-bottom-style: solid; /* table.border.bottom.style */ border-bottom-width: 2px; /* table.border.bottom.width */ border-bottom-color: #A8A8A8; /* table.border.bottom.color */ } #sxebjwowzx .gt_heading { background-color: #FFFFFF; /* heading.background.color */ border-bottom-color: #FFFFFF; } #sxebjwowzx .gt_title { color: #333333; font-size: 125%; /* heading.title.font.size */ padding-top: 4px; /* heading.top.padding - not yet used */ padding-bottom: 4px; border-bottom-color: #FFFFFF; border-bottom-width: 0; } #sxebjwowzx .gt_subtitle { color: #333333; font-size: 85%; /* heading.subtitle.font.size */ padding-top: 0; padding-bottom: 4px; /* heading.bottom.padding - not yet used */ border-top-color: #FFFFFF; border-top-width: 0; } #sxebjwowzx .gt_bottom_border { border-bottom-style: solid; /* heading.border.bottom.style */ border-bottom-width: 2px; /* heading.border.bottom.width */ border-bottom-color: #D3D3D3; /* heading.border.bottom.color */ } #sxebjwowzx .gt_column_spanner { border-bottom-style: solid; border-bottom-width: 2px; border-bottom-color: #D3D3D3; padding-top: 4px; padding-bottom: 4px; } #sxebjwowzx .gt_col_heading { color: #333333; background-color: #FFFFFF; /* column_labels.background.color */ font-size: 16px; /* column_labels.font.size */ font-weight: initial; /* column_labels.font.weight */ vertical-align: middle; padding: 5px; margin: 10px; overflow-x: hidden; } #sxebjwowzx .gt_columns_top_border { border-top-style: solid; border-top-width: 2px; border-top-color: #D3D3D3; } #sxebjwowzx .gt_columns_bottom_border { border-bottom-style: solid; border-bottom-width: 2px; border-bottom-color: #D3D3D3; } #sxebjwowzx .gt_sep_right { border-right: 5px solid #FFFFFF; } #sxebjwowzx .gt_group_heading { padding: 8px; /* row_group.padding */ color: #333333; background-color: #FFFFFF; /* row_group.background.color */ font-size: 16px; /* row_group.font.size */ font-weight: initial; /* row_group.font.weight */ border-top-style: solid; /* row_group.border.top.style */ border-top-width: 2px; /* row_group.border.top.width */ border-top-color: #D3D3D3; /* row_group.border.top.color */ border-bottom-style: solid; /* row_group.border.bottom.style */ border-bottom-width: 2px; /* row_group.border.bottom.width */ border-bottom-color: #D3D3D3; /* row_group.border.bottom.color */ vertical-align: middle; } #sxebjwowzx .gt_empty_group_heading { padding: 0.5px; color: #333333; background-color: #FFFFFF; /* row_group.background.color */ font-size: 16px; /* row_group.font.size */ font-weight: initial; /* row_group.font.weight */ border-top-style: solid; /* row_group.border.top.style */ border-top-width: 2px; /* row_group.border.top.width */ border-top-color: #D3D3D3; /* row_group.border.top.color */ border-bottom-style: solid; /* row_group.border.bottom.style */ border-bottom-width: 2px; /* row_group.border.bottom.width */ border-bottom-color: #D3D3D3; /* row_group.border.bottom.color */ vertical-align: middle; } #sxebjwowzx .gt_striped { background-color: #8080800D; } #sxebjwowzx .gt_from_md > :first-child { margin-top: 0; } #sxebjwowzx .gt_from_md > :last-child { margin-bottom: 0; } #sxebjwowzx .gt_row { padding: 8px; /* row.padding */ margin: 10px; border-top-style: solid; border-top-width: 1px; border-top-color: #D3D3D3; vertical-align: middle; overflow-x: hidden; } #sxebjwowzx .gt_stub { border-right-style: solid; border-right-width: 2px; border-right-color: #D3D3D3; padding-left: 12px; } #sxebjwowzx .gt_summary_row { color: #333333; background-color: #FFFFFF; /* summary_row.background.color */ padding: 8px; /* summary_row.padding */ text-transform: inherit; /* summary_row.text_transform */ } #sxebjwowzx .gt_grand_summary_row { color: #333333; background-color: #FFFFFF; /* grand_summary_row.background.color */ padding: 8px; /* grand_summary_row.padding */ text-transform: inherit; /* grand_summary_row.text_transform */ } #sxebjwowzx .gt_first_summary_row { border-top-style: solid; border-top-width: 2px; border-top-color: #D3D3D3; } #sxebjwowzx .gt_first_grand_summary_row { border-top-style: double; border-top-width: 6px; border-top-color: #D3D3D3; } #sxebjwowzx .gt_table_body { border-top-style: solid; /* table_body.border.top.style */ border-top-width: 2px; /* table_body.border.top.width */ border-top-color: #D3D3D3; /* table_body.border.top.color */ border-bottom-style: solid; /* table_body.border.bottom.style */ border-bottom-width: 2px; /* table_body.border.bottom.width */ border-bottom-color: #D3D3D3; /* table_body.border.bottom.color */ } #sxebjwowzx .gt_footnotes { border-top-style: solid; /* footnotes.border.top.style */ border-top-width: 2px; /* footnotes.border.top.width */ border-top-color: #D3D3D3; /* footnotes.border.top.color */ } #sxebjwowzx .gt_footnote { font-size: 90%; /* footnote.font.size */ margin: 0px; padding: 4px; /* footnote.padding */ } #sxebjwowzx .gt_sourcenotes { border-top-style: solid; /* sourcenotes.border.top.style */ border-top-width: 2px; /* sourcenotes.border.top.width */ border-top-color: #D3D3D3; /* sourcenotes.border.top.color */ } #sxebjwowzx .gt_sourcenote { font-size: 90%; /* sourcenote.font.size */ padding: 4px; /* sourcenote.padding */ } #sxebjwowzx .gt_center { text-align: center; } #sxebjwowzx .gt_left { text-align: left; } #sxebjwowzx .gt_right { text-align: right; font-variant-numeric: tabular-nums; } #sxebjwowzx .gt_font_normal { font-weight: normal; } #sxebjwowzx .gt_font_bold { font-weight: bold; } #sxebjwowzx .gt_font_italic { font-style: italic; } #sxebjwowzx .gt_super { font-size: 65%; } #sxebjwowzx .gt_footnote_marks { font-style: italic; font-size: 65%; } </style> <div id="sxebjwowzx" style="overflow-x:auto;overflow-y:auto;width:auto;height:auto;"><table class="gt_table" style="table-layout: fixed; width: 180px"> <colgroup> <col style="width: 60px"/> <col style="width: 60px"/> <col style="width: 60px"/> </colgroup> <tr> <th class="gt_col_heading gt_columns_bottom_border gt_columns_top_border gt_left" rowspan="1" colspan="1"> </th> <th class="gt_col_heading gt_columns_bottom_border gt_columns_top_border gt_left" rowspan="1" colspan="1"> </th> <th class="gt_col_heading gt_columns_bottom_border gt_columns_top_border gt_left" rowspan="1" colspan="1"> </th> </tr> <body class="gt_table_body"> <tr> <td class="gt_row gt_left" style="background-color: #9ACD32FF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left" style="background-color: #9ACD32FF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left" style="background-color: #9ACD32FF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> </tr> <tr> <td class="gt_row gt_left gt_striped" style="background-color: #00C5CDFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left gt_striped" style="background-color: #00C5CDFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left gt_striped" style="background-color: #00C5CDFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> </tr> <tr> <td class="gt_row gt_left" style="background-color: #3A5FCDFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left" style="background-color: #3A5FCDFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> <td class="gt_row gt_left" style="background-color: #3A5FCDFF; border-left-width: 1px; border-left-style: solid; border-left-color: #e6e6e6; border-right-width: 1px; border-right-style: solid; border-right-color: #e6e6e6; border-top-width: 1px; border-top-style: solid; border-top-color: #e6e6e6; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: #e6e6e6;"> </td> </tr> </body> </table></div> ]] --- ## `group_by()` & `summarise()` example For each type of crime, calculate average crime rate and standard deviation. ```r fbi %>% group_by(Type) %>% summarise(mean_rate = mean(Count/Population*70000, na.rm=TRUE), sd_rate = sd(Count/Population*70000, na.rm = TRUE)) ``` ``` ## # A tibble: 8 x 3 ## Type mean_rate sd_rate ## <fct> <dbl> <dbl> ## 1 Aggravated.assault 167. 113. ## 2 Burglary 630. 311. ## 3 Larceny.theft 1657. 626. ## 4 Legacy.rape 20.2 10.8 ## 5 Motor.vehicle.theft 244. 158. ## 6 Murder.and.nonnegligent.Manslaughter 4.60 4.23 ## 7 Rape 29.6 12.3 ## 8 Robbery 88.5 103. ``` --- class: inverse, center, middle # Let's put these <br>tools to use --- ## French fries data ```r data(french_fries, package="reshape2") ``` - data from sensory experiment conducted at Iowa State University in 2004 - investigators were interested in comparing effects of three different fryer oils on taste of fries ```r french_fries %>% head() ``` ``` ## time treatment subject rep potato buttery grassy rancid painty ## 61 1 1 3 1 2.9 0.0 0.0 0.0 5.5 ## 25 1 1 3 2 14.0 0.0 0.0 1.1 0.0 ## 62 1 1 10 1 11.0 6.4 0.0 0.0 0.0 ## 26 1 1 10 2 9.9 5.9 2.9 2.2 0.0 ## 63 1 1 15 1 1.2 0.1 0.0 1.1 5.1 ## 27 1 1 15 2 8.8 3.0 3.6 1.5 2.3 ``` --- ## Did the french fries taste worse over time? How do we define 'tasting well'? - Higher values of potato-y and buttery, lower values of grassy, rancid, painty - Compute averages of these scales for each time point - combination of `group_by` and `summarise` --- ## Did the french fries taste worse over time? (2) ```r french_fries %>% group_by(time) %>% summarise( m.potato = mean(potato, na.rm=TRUE), m.buttery = mean(buttery, na.rm=TRUE), m.grassy = mean(grassy, na.rm=TRUE), m.rancid = mean(rancid, na.rm=TRUE), m.painty = mean(painty, na.rm=TRUE) ) %>% head() ``` ``` ## # A tibble: 6 x 6 ## time m.potato m.buttery m.grassy m.rancid m.painty ## <fct> <dbl> <dbl> <dbl> <dbl> <dbl> ## 1 1 8.56 2.24 0.942 2.36 1.65 ## 2 2 8.06 2.72 1.18 2.85 1.44 ## 3 3 7.80 2.10 0.75 3.72 1.31 ## 4 4 7.71 1.80 0.742 3.60 1.37 ## 5 5 7.33 1.64 0.635 3.53 2.02 ## 6 6 6.67 1.75 0.674 4.08 2.34 ``` --- ## Did the french fries taste worse over time? (3) ```r avgs %>% ggplot(aes(x = time)) + geom_point(aes(y = m.potato)) + geom_point(shape=2, aes(y=m.rancid)) + ylab("Average") ``` 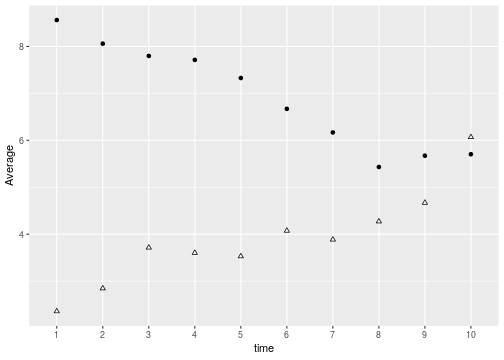<!-- --> --- class: yourturn # Your turn For this your turn use the `french_fries` data from the `reshape2` package: `data(french_fries, package="reshape2")` - Do ratings of potato-y show a difference between the different oils over time? - Draw a plot of the average potato-y rating by time, color by treatment. - How does this plot look like for the rancid rating? --- class: yourturn # Your turn For this your turn use the `french_fries` data from the `reshape2` package: `data(french_fries, package="reshape2")` - How much consistency do we see between ratings? For buttery and rancid ratings find the mean and the absolute difference between the two replicates (for each subject, each treatment and each time point). Use `dplyr` functions to find this summary dataset. - Are ratings more different between the two scales? What would you need to draw a side-by-side boxplot of the two ratings? Describe in words. - Are some subjects in the study more consistent than others? Show the variability in the potato-y ratings by subjects. Order subjects from least variability to most. --- class: yourturn # Your turn For this your turn use the `french_fries` data from the `reshape2` package: `data(french_fries, package="reshape2")` For each subject, determine how many records are missing (either absent or NA). Expand on the above summary of missing values by taking time into account. Plot the result: plot number of missing values by week, facet by subject. Is the result surprising? --- ## Resources - reference/document: http://dplyr.tidyverse.org/reference/ - RStudio cheat sheet for [dplyr](https://github.com/rstudio/cheatsheets/raw/master/data-transformation.pdf) - Artwork by [@allison_horst](https://twitter.com/allison_horst?ref_src=twsrc%5Egoogle%7Ctwcamp%5Eserp%7Ctwgr%5Eauthor) - https://datasciencebox.org/