class: center, middle, inverse, title-slide # Cleaning data: <br>messy 3 & 4 --- class: inverse, middle, center # Messy (3): ## Multiple observational units are stored in the same table. --- class: inverse, center, middle # Keys & Measurements --- ## Finding your keys - Example (1) 100 patients are randomly assigned to a treatment for heart attack, <br> measured 5 different clinical outcomes. <br><br> -- - **key**: patient ID - **factor variable (design)**: treatment - **measured variables**: 5 clinical outcomes --- ## Finding your keys - Example (2) Randomized complete block trial with four fields, four different types of <br> fertilizer, over four years. Recorded total corn yield, and fertilizer run off. <br><br> -- - **key**: fields, types of fertilizer, year - **measurement**: total corn yield, fertilizer run off --- ## Finding your keys - Example (3) Cluster sample of twenty students in thirty different schools. For each school, recorded distance from ice rink. For each student, asked how often they go ice skating, and whether or not their parents like ice skating <br><br> -- - **key**: student ID, school ID - **measurement**: distance to rink, # of times ice skating, parents' preference --- ## Finding your keys - Example (4) For each person, recorded age, sex, height and target weight, and then at multiple times recorded their weight <br><br> -- - **key**: *patient ID*, date - **measurement**: *age, sex, height, target weight*, current weight *only patient ID is needed for variables in italics* --- ## Messy (3) **Messy (3)**: Multiple observational units are stored in the same table. **What does that mean?** The key is split, - i.e. for some values all key variables are necessary, while other values only need some key variables. 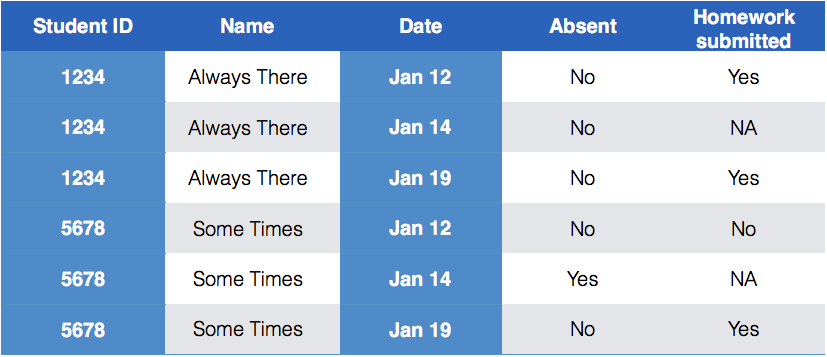 --- ## Why do we need to take care <br> of split keys? - Data redundancy introduces potential problems - same student *should* have the same student ID - to check data consistency, we split data set into parts - this process is called **normalizing** - normalization reduces overall data size - useful way of thinking about objects under study --- ## Tidying Messy (3) Splitting into separate datasets: 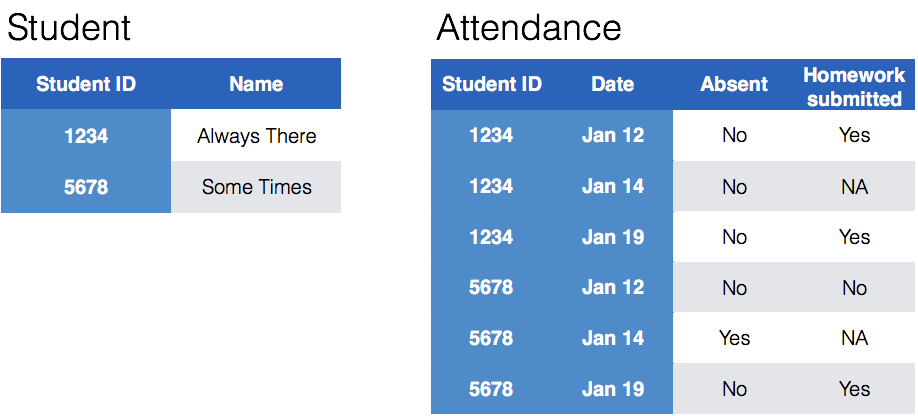 --- ## Example: Box office gross The-Numbers website publishes [weekly charts](http://www.the-numbers.com/weekend-box-office-chart) of the gross income of all movies playing across the US. A set of cleaned data called `box` with movies for the last five years is available in the `classdata` package. ```r # devtools::install_github("haleyjeppson/classdata") data(box, package = "classdata") head(box, 4) ``` ``` ## Rank Rank.Last.Week Movie Distributor Gross Change Thtrs. Per.Thtr. ## 1 1 1 Joker Warner Bros. 55861403 -42 4374 12771 ## 2 2 NA The Addams Family United Artists 30300007 NA 4007 7562 ## 3 3 NA Gemini Man Paramount Pictures 20552372 NA 3642 5643 ## 4 4 2 Abominable Universal 6072235 -49 3496 1737 ## Total.Gross Week Date ## 1 193590190 2 2019-10-11 ## 2 30300007 1 2019-10-11 ## 3 20552372 1 2019-10-11 ## 4 47873585 3 2019-10-11 ``` </br> What are the key variables? Why is the key split? --- ## Keys and measurements - **Key variables**: `Movie` name, `Date` and `Distributor`. - **Measurement variables**: `Gross`, `Thtrs.` - All other variables are derived from these variables - **Good practice**: re-calculate the derived variabes to check for consistency. --- ## Taking care of the split key **Plan**: - separate movie information from box office information **Idea for separation**: - we want to get a set of movies together with their distributor and *ideally* with their release date (which we do not have) - instead of release date, we can get the date of the first time that we see a movie in the boxoffice - let's also keep track of how many weeks a movie has been released at that time (should be 1 - when will it be different?) --- class: yourturn # Your turn For this your turn use the `box` data from the `classdata` package. - **Big goal**: we want to create a new dataset `movie` that consists of movie, distributor, date of first time the movie shows up in the box office, and the number of weeks the movie has been released at that time. - What are the key variables for the new dataset? - For the key variable(s), use `summarize()` to find the first time a movie shows up in the box office and find the related number of weeks. --- ## Key variables Does `Movie` uniquely describe a movie? ```r movies <- box %>% select(Movie, Distributor) %>% distinct() ``` Does that make a movie unique? ```r movies %>% count(Movie) %>% arrange(desc(n)) ``` ``` ## # A tibble: 4,144 x 2 ## Movie n ## <chr> <int> ## 1 Beauty and the Beast 2 ## 2 Breathe 2 ## 3 Champion 2 ## 4 Concussion 2 ## 5 Entertainment 2 ## 6 Girlhood 2 ## 7 Gold 2 ## 8 Holy Hell 2 ## 9 Iceman 2 ## 10 Leviathan 2 ## # … with 4,134 more rows ``` --- ## Movie data - take 2 Get the week info for the first time we see each movie and distributor combo: ```r movies <- box %>% group_by(Movie, Distributor) %>% summarise( firstDate = Date[which.min(Week)], firstWeek = min(Week, na.rm=TRUE)) head(movies) ``` ``` ## # A tibble: 6 x 4 ## # Groups: Movie [6] ## Movie Distributor firstDate firstWeek ## <chr> <chr> <date> <dbl> ## 1 '71 Roadside Attractions 2015-02-27 1 ## 2 [REC] 4: Apocalypse Magnolia Pictures 2015-01-02 1 ## 3 1,000 Rupee Note Kino Lorber 2016-09-23 1 ## 4 1,000 Times Goodnight Film Movement 2014-10-24 1 ## 5 10 Cloverfield Lane Paramount Pictures 2016-03-11 1 ## 6 10 Days in a Madhouse Cafe Pictures 2015-11-20 2 ``` --- ## Looking into inconsistencies ```r movies %>% group_by(Movie) %>% mutate(n = n()) %>% arrange(desc(n)) ``` ``` ## # A tibble: 4,172 x 5 ## # Groups: Movie [4,144] ## Movie Distributor firstDate firstWeek n ## <chr> <chr> <date> <dbl> <int> ## 1 Beauty and the Beast Lopert Pictures Cor... 2016-02-12 1 2 ## 2 Beauty and the Beast Walt Disney 2017-03-17 1 2 ## 3 Breathe Bleecker Street 2017-10-13 1 2 ## 4 Breathe Film Movement 2015-09-11 1 2 ## 5 Champion ArtAffects 2017-05-26 2 2 ## 6 Champion Well Go USA 2018-05-11 1 2 ## 7 Concussion Radius 2013-10-04 1 2 ## 8 Concussion Sony Pictures 2015-12-25 1 2 ## 9 Entertainment B4U Movies 2014-08-08 1 2 ## 10 Entertainment Magnolia Pictures 2015-11-13 1 2 ## # … with 4,162 more rows ``` --- ## Using IMDb: Beauty and the Beast According to IMDb there are at least four movies released with the name Beauty and the Beast: 2017 (Walt Disney Pictures), 2014 (Spanish Production), 1991 (Walt Disner Pictures), and 1946 (French Production, released by Lopert Films in the US). Can't distinguish between the 2017 and the 1991 movie. The Lopert produced movie was only shown for two weeks in at most 3 theaters. ```r box %>% dplyr::filter(Movie=="Beauty and the Beast") %>% tail(6) ``` ``` ## Rank Rank.Last.Week Movie Distributor Gross Change Thtrs. Per.Thtr. ## 14 2 2 Beauty and the Beast Walt Disney 23652605 -48 3969 5959 ## 15 2 1 Beauty and the Beast Walt Disney 45420743 -50 4210 10789 ## 16 1 1 Beauty and the Beast Walt Disney 90426717 -48 4210 21479 ## 17 1 NA Beauty and the Beast Walt Disney 174750616 NA 4210 41508 ## 18 72 65 Beauty and the Beast Lopert Pictures Cor... 4718 -43 3 1573 ## 19 65 NA Beauty and the Beast Lopert Pictures Cor... 8264 NA 1 8264 ## Total.Gross Week Date ## 14 430946639 4 2017-04-07 ## 15 393337585 3 2017-03-31 ## 16 319032604 2 2017-03-24 ## 17 174750616 1 2017-03-17 ## 18 20324 2 2016-02-19 ## 19 8264 1 2016-02-12 ``` --- ## Using IMDb (2) - Girlhood is the name of two movies - one that was released in 2003, one in 2014; most likely the Oct 4 boxoffice mention is only mistakenly referring to the 2003 movie ```r box %>% dplyr::filter(Movie=="Girlhood") %>% head(6) ``` ``` ## Rank Rank.Last.Week Movie Distributor Gross Change Thtrs. Per.Thtr. Total.Gross Week Date ## 1 80 88 Girlhood Strand 1763 278 1 1763 60019 15 2015-05-08 ## 2 88 99 Girlhood Strand 467 -67 1 467 58148 14 2015-05-01 ## 3 99 100 Girlhood Strand 1431 343 3 477 56566 13 2015-04-24 ## 4 100 102 Girlhood Strand 323 55 1 323 54712 12 2015-04-17 ## 5 101 NA Girlhood 209 NA 1 209 53938 598 2015-04-10 ## 6 102 81 Girlhood Strand 209 -90 5 42 52907 11 2015-04-10 ``` --- ## Using IMDb: - Mama Africa refers to two movies, one released in 2002, one in 2011; likely the duplicate on Jan 19 is erroneous, but we still don't know which of the two movies is showing (in 1 theater) ```r box %>% dplyr::filter(Movie=="Mama Africa") ``` ``` ## Rank Rank.Last.Week Movie Distributor Gross Change Thtrs. Per.Thtr. Total.Gross ## 1 88 79 Mama Africa ArtMattan Productions 481 -72 2 241 9808 ## 2 79 67 Mama Africa ArtMattan Productions 1689 -52 2 845 8123 ## 3 67 NA Mama Africa ArtMattan Productions 3495 NA 1 3495 3495 ## 4 69 NA Mama Africa 3187 NA 1 3187 3187 ## Week Date ## 1 3 2018-02-02 ## 2 2 2018-01-26 ## 3 1 2018-01-19 ## 4 816 2018-01-19 ``` --- ## why do we normalize? - Normalization helps identify inconsistencies in data - Checking up on inconsistencies is a lot of manual labor --- ## Resources - reference/document: http://tidyr.tidyverse.org/reference/ - RStudio cheat sheet for [tidyr](https://github.com/rstudio/cheatsheets/blob/master/data-import.pdf)